快速入门#
任务与目标#
本节将详细介绍如何使用PyPTO框架实现一个简单的Softmax算子,并通过测试用例验证其正确性。通过本节的学习,您将了解如何使用PyPTO的API来构建自定义算子。并且在程序完成后,您还可以通过PyPTO Toolkit可视化工具查看计算图结构,并观测算子的各项性能数据。
Softmax算子实现的example代码位于:softmax.py,用户可结合代码示例理解本节内容。
算子设计规格#
表1 Softmax算子设计规格
name |
shape |
data type |
format |
|---|---|---|---|
inputs(输入) |
(-1, 32, 1, 256) |
float |
ND |
outputs(输出) |
(-1, 32, 1, 256) |
float |
ND |
数学表达式
\(M = \max(z),\quad \text{SoftMax}(z_i) = \frac{\exp(z_i - M)}{\sum_j \exp(z_j - M)}\)
使用的主要接口
基础计算接口:exp,sum,/ (div),amax,-(sub)
导入PyPTO模块#
在开始实现Softmax算子之前,首先需要导入PyPTO、PyTorch和Numpy模块。PyPTO模块提供了Tensor操作和编译能力,而PyTorch和Numpy模块用于结果验证。
import pypto
import torch
import numpy as np
from numpy.testing import assert_allclose
核心代码逻辑#
实现核心计算函数。
PyPTO提供了丰富的Operation(操作)接口,用于实现不同的计算逻辑。开发者可以根据算子数学表达式组合不同的Operation接口,实现复杂的计算逻辑。以下是Softmax算子的核心计算函数实现:
def softmax_core(x: pypto.Tensor) -> pypto.Tensor: row_max = pypto.amax(x, dim=-1, keepdim=True) # 计算行最大值 sub = x - row_max # 值归一化 exp = pypto.exp(sub) # 指数运算 esum = pypto.sum(exp, dim=-1, keepdim=True) # 求和 return exp / esum # 概率归一化
实现Softmax Kernel函数。
为了使计算逻辑能够在硬件上高效运行,需要实现Softmax Kernel函数,并通过@pypto.frontend.jit装饰器将计算图转换为硬件指令,并在其中定义数据切分和循环处理等策略。在调用时直接传入PyTorch Tensor,PyPTO框架会自动处理Tensor的类型转换。
@pypto.frontend.jit def softmax_kernel( input_tensor: pypto.Tensor([pypto.DYNAMIC, ...], pypto.DT_FP32), output_tensor: pypto.Tensor([pypto.DYNAMIC, ...], pypto.DT_FP32), ): bs, seqlen, head, dim = input_tensor.shape tile_b = 1 # Process one batch at a time b_loop = bs // tile_b # Tiling shape setting for efficient execution pypto.set_vec_tile_shapes(1, 4, 1, 64) for idx in pypto.loop(0, b_loop, 1, name="LOOP_L0_bIdx", idx_name="idx"): b_offset = idx * tile_b b_offset_end = (idx + 1) * tile_b input_view = input_tensor[b_offset:b_offset_end, :seqlen, :head, :dim] softmax_out = softmax_core(input_view) output_tensor[b_offset:, ...] = softmax_out
其中,为了提高算子的计算效率,可以通过set_vec_tile_shapes或set_cube_tile_shapes接口,指定操作的分块(Tiling)方式。这种Tiling配置将计算分解为硬件友好的Tile粒度(如64),可优化内存访问和并行计算效率。
pypto.set_vec_tile_shapes(1, 4, 1, 64)
测试用例#
为了验证Softmax算子的正确性,编写一个测试用例。该测试用例使用PyTorch Tensor作为输入,通过PyPTO kernel进行计算,并与PyTorch的内置Softmax函数的结果进行对比。在开始执行PyPTO和PyTorch相关代码之前,需要指定对应的Device ID,或者通过torch.npu接口获取当前的Device ID。
def test_softmax(device_id: int = None, run_mode: str = "npu", dynamic: bool = True) -> None:
device = f'npu:{device_id}' if (run_mode == "npu" and device_id is not None) else 'cpu'
shape = (32, 32, 1, 256)
x = torch.rand(shape, dtype=torch.float, device=device)
y = torch.zeros(shape, dtype=torch.float, device=device)
softmax_kernel(x, y) # default dim: -1
golden = torch.softmax(x, dim=-1).cpu()
y = y.cpu()
max_diff = np.abs(y.numpy() - golden.numpy()).max()
print(f"Input shape: {x.shape}")
print(f"Output shape: {y.shape}")
print(f"Max difference: {max_diff:.6f}")
if run_mode == "npu":
assert_allclose(np.array(y), np.array(golden), rtol=3e-3, atol=3e-3)
print("✓ Softmax test passed")
print()
编译与执行#
切换到示例代码所在目录,在已安装PyPTO的环境中运行:
# 配置CANN环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 设置设备ID
export TILE_FWK_DEVICE_ID=0
#执行脚本
python3 softmax.py
程序执行成功后,显示以下信息:
Input shape: torch.Size([32, 32, 1, 256])
Output shape: torch.Size([32, 32, 1, 256])
✓ Softmax test passed
同时,会在${work_path}/output/output_*/目录(*代表时间戳)下生成编译和执行的结果文件。
查看计算图#
PyPTO程序在编译过程中,会自动生成由Tensor和Operation组合而成的图结构,即计算图。该计算图经过PyPTO编译优化流程,完成从原始计算图到可执行图的编译过程,最终生成可在昇腾硬件环境中运行的可执行代码,以实现实际的计算任务。用户可借助PyPTO Toolkit可视化工具查看计算图中的关键信息。
右键单击${work_path}/output/output_*/program.json文件,在弹出的菜单中选择“使用PyPTO Toolkit打开”。
program.json文件包含了Execute Graph和Block Graph的汇总信息,图中的关键信息为:左右两边的卡片为Tensor节点(代表输入/输出数据)、中间卡片为调用节点(带有fx标识,单击可以实现信息钻取)。
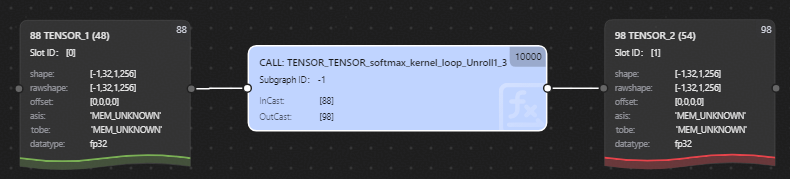
双击中间卡片逐层钻取到下图所示的Execute Graph。
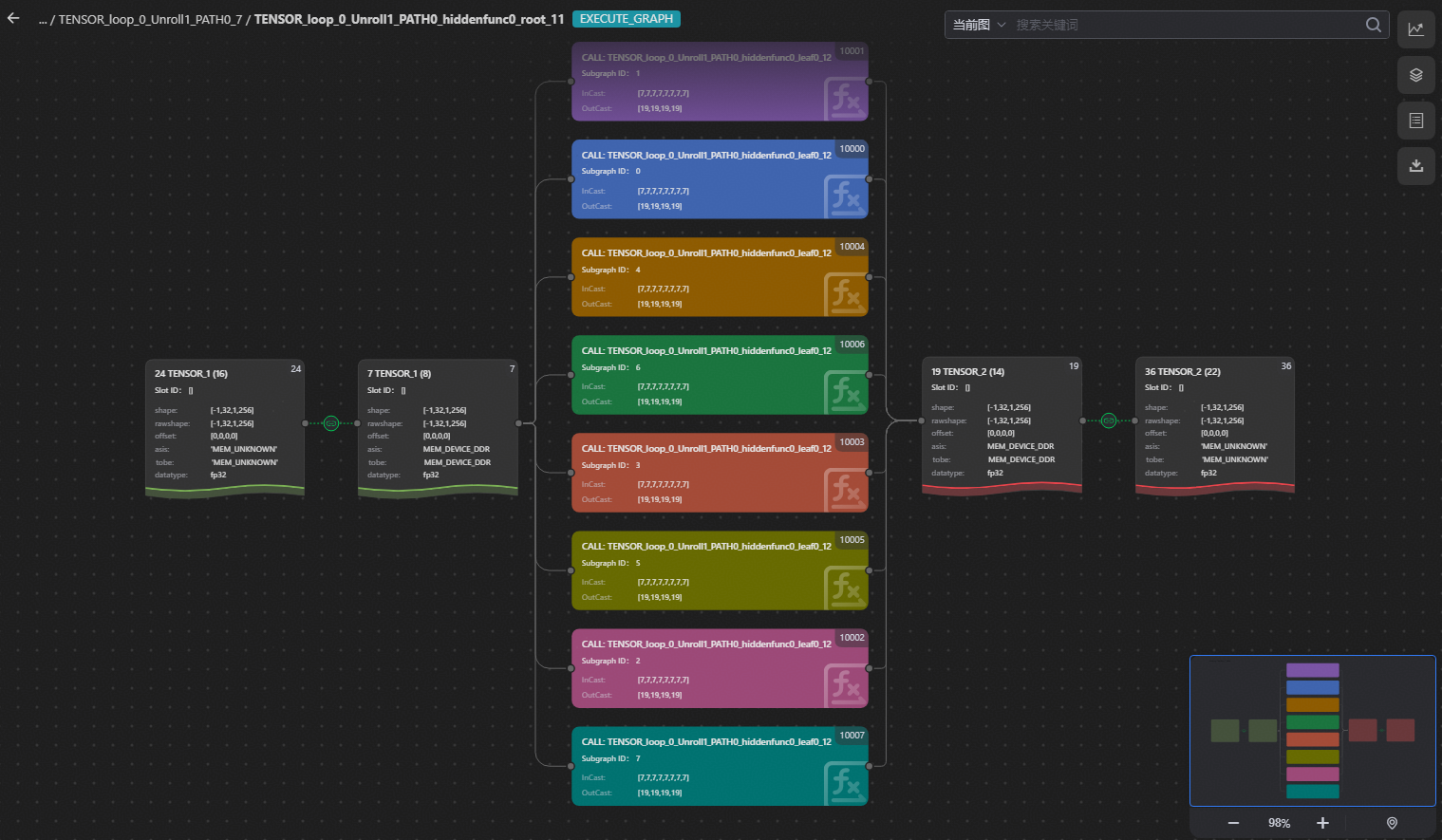
图中不同的色块(CALL:TENSOR_xx)分别代表一个调用节点,表示该计算图被划分成不同的Block Graph子图。
双击上图的调用节点,可以看到Block Graph子图信息,标识着任务的具体执行过程。

放大后可以看到图中具体的Tensor和Operation节点信息和连接关系:
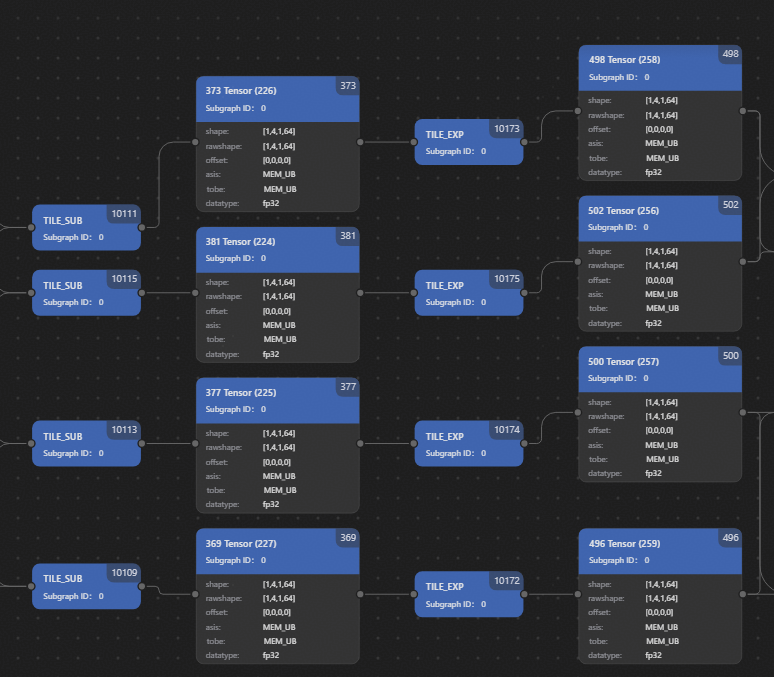
查看泳道图#
泳道图用于直观展示计算图的实际调度与执行过程,清晰呈现任务的执行顺序和耗时信息,帮助开发者分析算子性能瓶颈。下面将介绍如何采集泳道图数据,并通过PyPTO Toolkit查看泳道图。
通过给@pypto.frontend.jit装饰器的入参debug_options配置图执行阶段调试开关启动性能数据采集功能。
@pypto.frontend.jit( debug_options={"runtime_debug_mode": 1} )
重新执行算子程序。
python3 softmax.py在${work_path}/output/output_*/目录(*代表时间戳)下生成泳道图数据文件,文件名为:merged_swimlane.json。
通过PyPTO Toolkit插件查看泳道图。
右键单击merged_swimlane.json,在弹出的菜单中选择“使用PyPTO Toolkit打开”,如下图所示。
图1 泳道图界面
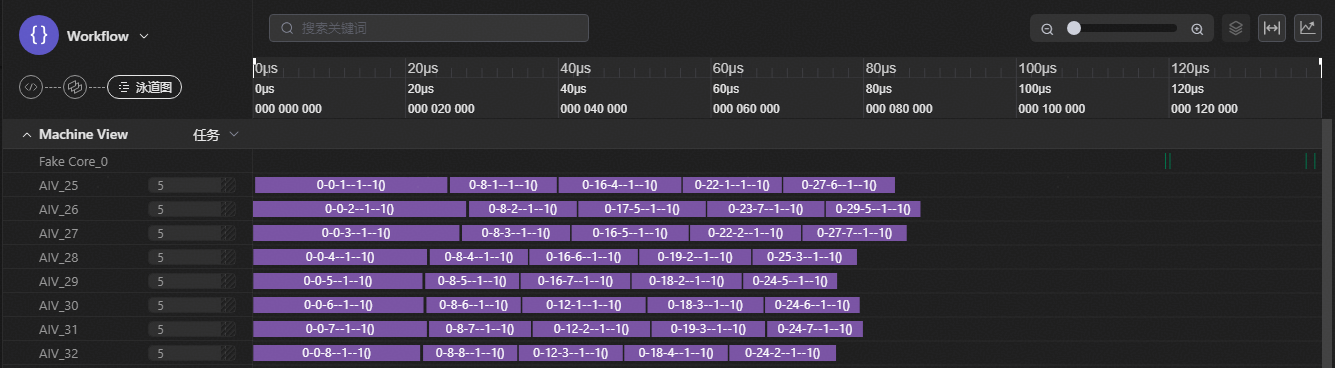
上图中带有色块的部分即为泳道,展示了每个AIC/AIV上的任务执行情况。泳道条目的长度对应任务的耗时,能够直观地反映计算的密集程度。用户可以通过观察相邻泳道之间的空闲间隔(如图中的黑色区域,或称气泡)以及耗时较长的泳道条目,来分析可能存在的性能瓶颈问题。