简介#
PyPTO(发音:pai p-t-o)是CANN推出的一款面向AI加速器的高效编程框架,旨在简化算子开发流程,同时保持高性能计算能力。该框架采用创新的PTO(Parallel Tensor/Tile Operation)编程范式,以基于Tile的编程模型为核心设计理念,通过多层次的计算图表达,将用户通过API构建的AI模型从高层次的Tensor计算图逐步编译成硬件指令,最终生成可在目标平台上高效执行的代码,并由设备侧以MPMD(Multiple Program Multiple Data)方式调度执行。
核心架构#
PyPTO框架采用分层架构设计,从用户API到底层硬件执行,共分为以下几个层次:
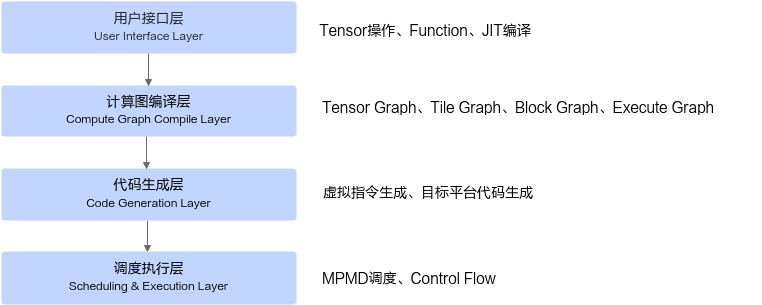
用户API层(User Interface Layer):是PyPTO框架与开发者交互的接口层,提供Python友好的编程接口,使开发者能够以直观的方式表达计算逻辑,而无需深入了解底层硬件实现细节。
计算图编译层(Compute Graph Compile Layer):PyPTO采用多层级计算图表达,支持从高到低多个抽象层次的计算图的优化和转换。
Tensor Graph:高层次的Tensor操作,贴近算法设计者的数学表达式。
Tile Graph:硬件感知的Tile操作,充分利用硬件并行性和内存层次结构。
Block Graph:子图分区,支持并行执行和资源管理。
Execute Graph:执行图,包含依赖关系和调度信息。
编译过程通过模块化的Pass实现,每个阶段由多个Pass组成,负责特定阶段优化或转换任务。
Tensor Graph阶段:实现和硬件无关的图优化,包括冗余操作消除、类型转换、内存冲突推断等。
Tile Graph阶段:根据TileShape进行Tile展开,实现Tile级别的优化,包括内存类型分配、移动操作生成、子图切分等。
Block Graph阶段:切分生成计算子图,进行Block级别的优化,包括乱序调度、内存重用、同步点插入等。
Execute Graph阶段:整合计算子图信息,编排生成最终的执行图。
代码生成层(Code Generation Layer):将优化后的计算图转换为目标平台的可执行代码。
虚拟指令生成:从Execute Graph生成PTO虚拟指令代码(PTO Virtual Instructions)。
目标平台编译:将虚拟指令编译为目标平台代码。
调度执行层(Scheduling & Execution Layer):负责将可执行代码在设备上调度执行。
MPMD调度:可执行代码在设备上通过MPMD方式调度到设备处理器核。
控制流执行:管理任务依赖关系,执行控制流逻辑。
核心特性#
技术创新点:
基于Tile的编程模型:计算基于Tile(硬件感知的数据块)进行,充分利用硬件的并行计算能力和内存层次结构。
多层级计算图表达和优化:通过计算图编译层将Tensor Graph转换为Tile Graph、Block Graph和Execute Graph,每一步都包含一系列Pass优化流程。
自动化代码生成:编译结果通过代码生成层生成PTO虚拟指令代码,然后通过编译器编译为目标平台的可执行代码。
MPMD执行调度:可执行代码被加载到设备侧,通过MPMD方式调度到设备处理器核,实现高效并行执行。
完整的工具链支持:全流程的编译中间产物和运行时性能数据可以通过IDE集成的工具链进行可视化,以便识别性能瓶颈。开发者还可以通过工具链控制编译和调度行为。
Python友好API:提供直观的Tensor级别抽象,贴近算法开发者的思维模式,支持动态Shape和符号化编程。
分层抽象设计:对不同开发者暴露不同的抽象层次,算法开发者使用Tensor层次,性能专家使用Tile层次,系统开发者使用Block层次。
适用场景#
PyPTO适用于以下场景:
深度学习算子开发:快速实现各种神经网络算子。
大模型开发:支持Attention、MoE、FFN等大模型组件。
动态Shape处理:支持动态Batch Size等动态Shape场景。
设计理念#
传统的模型开发通常分为算法开发人员和算子开发人员。这种分工的根源在于高性能算子开发的复杂性:算子开发人员不仅需要理解算子的数学计算属性,还必须考虑如何将其转换为对硬件友好的执行方式。这类似于早期CPU时代,在乱序执行和编译器技术尚未成熟时,程序员需要手动安排流水线指令。
为了降低这种复杂性,PyPTO提出了一种新的编程框架设计理念,旨在简化算子开发流程,同时保留高性能计算的潜力。
计算层设计
计算层的设计理念是尽可能贴近算法设计者的数学表达式,使用Tensor而非单个元素来描述计算过程。用户通过API构建的AI模型通过Tensor Graph表达,这种设计保留了最大化的优化潜力,包括:
内存布局优化:自动优化数据在内存中的排布方式
数据搬运优化:最小化数据在不同内存层次间的传输
多算子联合优化:识别并融合可优化的算子组合
通过Tensor作为基本数据单位,计算层能够更自然地表达复杂的数学运算,同时为后续的编译优化提供丰富的信息。
编译层设计
编译层是连接计算层和执行层的关键环节,负责将Tensor Graph转换为硬件友好的执行形式。编译过程通过多阶段的Lowering Pipeline实现:
Tensor Graph到Tile Graph:通过编译Pass将Tensor操作转换为Tile操作,选择Tiling策略,进行布局变换、Tile融合、Tile重排序等。
Tile Graph到Block Graph:将Tile图分区为子图,检测同构子图,规范化Block Graph,追踪依赖关系。
Block Graph到Execute Graph:构建执行图,分析Block Graph之间的依赖关系,规划全局资源,生成调度提示。
每个阶段都包含多个优化Pass,通过模块化的图变换和优化流程,将计算层保留的优化空间转化为实际性能提升。
编译层提供了以下核心能力:
快速可用:保证第一时间生成可运行的结果,满足快速开发的需求。
灵活调优:支持性能敏感的配置调整,方便开发者根据实际需求进行优化。
深度优化:允许高级用户深度定制编译流程,追求极致性能。
执行层设计
执行层负责将编译后的代码转换为硬件友好的指令并执行。执行过程包括:
代码生成:编译结果通过CodeGen生成底层PTO虚拟指令代码。
目标平台编译:通过编译器将虚拟指令代码编译成目标NPU平台的可执行代码。
MPMD调度:可执行代码被加载到设备侧,通过MPMD方式调度到设备上的处理器核。
通过自动化代码生成技术,执行层能够根据硬件特性自动生成最优的执行指令,充分释放硬件算力。这种设计避免了传统算子开发中手动调整硬件指令的复杂性,同时确保了高性能计算的实现。
工具链设计
PyPTO提供了完整的工具链支持,包括:
编译中间产物可视化:支持在编译的不同阶段(如Tensor Graph、Tile Graph、Block Graph、Execute Graph等)保存中间产物(计算图),便于调试和分析。
运行时性能分析:收集并可视化运行时性能数据(泳道图),帮助识别性能瓶颈。
编译和调度控制:开发者可以通过工具链控制编译Pass的执行和调度行为,实现深度定制。
通过上述设计理念,PyPTO实现了算法开发与算子开发的高效协同,显著降低了算子开发的复杂性,同时保留了高性能计算的能力。
支持的产品型号#
PyPTO支持在如下产品型号使用:
Ascend 950PR/Ascend 950DT
Atlas A3 训练系列产品/Atlas A3 推理系列产品
Atlas A2 训练系列产品/Atlas A2 推理系列产品