功能调试#
编译与执行流程#
当开发者完成对Tensor的定义,并通过一系列对Tensor的基本运算构建完整的计算流程后,系统会生成由Tensor和Operation交错连接的图结构,即计算图。该计算图经过PyPTO编译优化流程,完成从原始计算图到可执行图的编译过程,最终生成可在昇腾硬件环境中运行的可执行代码,以实现实际的计算任务。
图编译流程#
下图展示了完整的计算图编译过程,Tensor Graph、Tile Graph、Block Graph阶段会经历多个Pass的优化,最终通过Execute Graph阶段整合图信息,编程生成最终的硬件执行图。
具体Pass列表请参见:framework/src/passes/pass_mgr/pass_manager.cpp文件。
图1 计算图编译流程
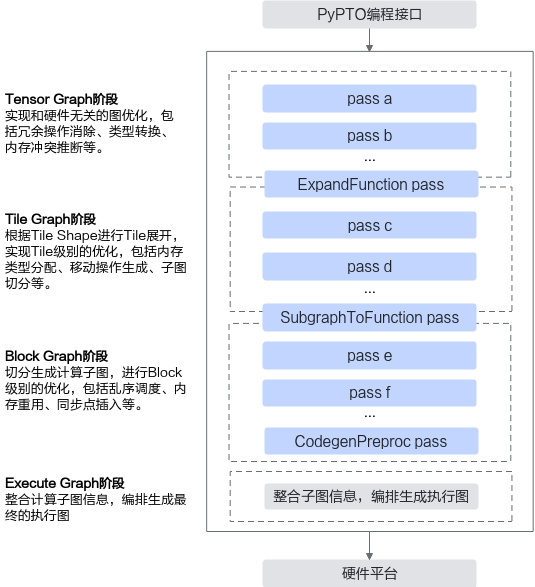
计算图编译各阶段生成的图分别为Tensor Graph、Tile Graph、Block Graph,Execute Graph,这些图是编译过程中的关键产物,表征了PyPTO程序从抽象计算描述到硬件执行的完整编译流程。
Tensor Graph:Tensor Graph由Tensor和Operation节点构成,用于描述用户定义的计算流程。该图不涉及Tile展开与内存层级等底层语义,仅作为高层计算逻辑的表达。基于Tensor Graph的优化主要集中在与硬件无关的通用图优化技术上,例如冗余节点消除、常量折叠等。
Tile Graph:Tile Graph由Tile和TileOp构成。Tensor Graph根据TileShape展开,将Tensor分解为Tile,将Operation分解为TileOp。Tile Graph依据TileOp信息以及目标硬件的内存层级,自动推导Tile的存储位置,并在必要时插入内存搬运节点,确保数据在不同内存层级之间正确传输。
Block Graph:Block Graph通过将Tile Graph切分为多个子图,使得每个子图可以调度运行在单个AI Core上。Block Graph用于硬件相关的优化,包括指令编排、片上内存分配、同步操作插入等,从而提升硬件执行效率。
Execute Graph:Execute Graph是编译流程的最终产物,整合了所有优化结果,精确描述各Block Graph之间的依赖关系,用于设备调度器的调度执行。
借助PyPTO Toolkit可视化工具,可以直观地查看计算图结构,了解计算图的节点信息,从而帮助开发者更便捷地进行算子功能调试。
图执行流程#
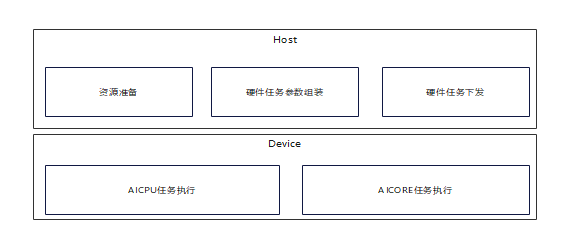
下图展示了从资源准备、任务下发到计算运行的完整执行过程。
资源准备阶段:根据Execute Graph中描述的执行资源信息,向执行硬件申请如workspace内存、Stream等全局资源。
任务参数组装和下发阶段:PyPTO的硬件执行任务分为AI CPU任务和AI Core任务。完成这两类任务所需的参数组装和任务配置后,提交给RTS以完成任务下发。
任务执行阶段:通过AI CPU和AI Core之间类Client-Server架构的紧密配合,完成整个计算任务的执行。AI CPU基于Execute Graph完成子任务的解析和分发,AI Core则负责接收AI CPU分发的子任务并完成运行。
在执行前,可以启用泳道图的采集和输出,利用PyPTO Toolkit可视化工具,直观查看各个子任务在AIC/AIV上的核间并行关系及前后执行顺序,从而帮助开发者更便捷地了解整体流水线分布,并进行针对性的算子性能优化。
图2 计算图执行流程
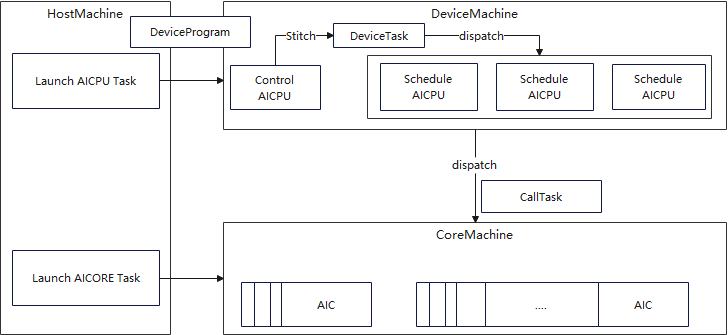
下图展示了PyPTO任务在硬件运行时的AI CPU与AI Core的关系,以及详细的运行流程。主要过程概括为:HostMachine初始化资源>DeviceMachine通过Stitch生成DeviceTask并调度CallTask>CoreMachine执行CallTask>DeviceProgram协调整个流程。
HostMachine:运行在Host侧,负责实际的硬件任务执行,包括资源准备、任务组装等。
DeviceMachine:运行在AI CPU侧,基于Execute Graph等执行态数据,负责AI Core执行子任务的分发和调度。具体流程为:Control-AICPU通过Stitch(字面意为“缝合”)将多个无依赖关系的Loop内的CallTask整合到一个DeviceTask中,以打破循环边界并最大化CallTask的并行度;Schedule-AICPU基于DeviceTask完成AI Core-CallTask的分发和管理。每个DeviceTask在3个Schedule-AICPU之间共享,各Schedule-AICPU根据所管理的AIC/AIV核的空闲状态,从DeviceTask中提取就绪的CallTask下发执行。
CoreMachine:运行在AI Core侧,负责接收来自AI CPU分发的CallTask并完成执行。CallTask是在AIC/AIV上运行的最小单元,由一系列CCE指令组成,用于在AI Core上执行具体的搬运和计算任务。
DeviceProgram:DeviceProgram是每个PyPTO算子在Device侧运行的核心数据,由Execute Graph中描述的信息结合硬件资源管理生成。
图3 执行态运行示意图
NPU上板调试#
如果图编译或图执行流程中出现错误或结果不符合预期,可以启用调试模式,生成不同阶段的计算图文件。计算图描述PyPTO程序计算流程的结构,由多个计算节点和数据节点组成。它通过有向无环图(DAG)的形式表示数据流动和计算逻辑,表征了PyPTO程序从抽象计算描述到硬件执行的完整编译流程。本节将介绍如何采集并查看计算图,并展示图中的关键信息。
开启调试模式#
开启图编译阶段调试模式开关。
@pypto.frontend.jit( debug_options={"compile_debug_mode": 1} )
执行用例。
python3 examples/02_intermediate/operators/softmax/softmax.py执行成功,在${work_path}/output/output_*/目录(*代表时间戳)下生成不同阶段的计算图文件(.json格式)。
├── Pass_<NNN>_ExpandFunction │ ├── After_<NNN>_ExpandFunction_TENSOR_s0_Unroll1_PATH0_4.json # pass优化后的计算图文件 │ ├── After_<NNN>_ExpandFunction_TENSOR_s0_Unroll1_PATH0_4.tifwkgr # 用户暂不需要关注 │ ├── Before_<NNN>_ExpandFunction_TENSOR_s0_Unroll1_PATH0_4.json # pass优化前的计算图文件 │ ├── Before_<NNN>_ExpandFunction_TENSOR_s0_Unroll1_PATH0_4.tifwkgr # 用户暂不需要关注 │ └── ExpandFunctionTENSOR_s0_Unroll1_PATH0_4.log ├── program.json # 记录function name, semantic label等静态信息 ├── ...
其中
<NNN>表示 Pass 执行序号,不同版本下可能变化(例如 004、005 等),实际以生成结果为准。
查看计算图#
下面将选取计算图各编译阶段的最后一张计算图,并使用PyPTO Toolkit可视化工具,帮助用户了解各类计算图上的关键信息,帮助开发者进行问题定位。
Tensor Graph:Before_004_ExpandFunction_TENSOR_loop_0_Unroll1_PATH0_hiddenfunc0_8.jsonTile Graph:Before_026_SubgraphToFunction_TENSOR_loop_0_Unroll1_PATH0_hiddenfunc0_8.jsonBlock Graph:After_036_CodegenPreproc_TENSOR_loop_0_Unroll1_PATH0_hiddenfunc0_8_LEAF_program_id_00_15536366383870408930.jsonExecute Graph:After_036_CodegenPreproc_TENSOR_loop_0_Unroll1_PATH0_hiddenfunc0_8_ROOT.json
通过PyPTO Toolkit查看Tensor Graph。
右键单击Before_004_ExpandFunction_TENSOR_loop_0_Unroll1_PATH0_hiddenfunc0_8.json文件,在弹出的菜单中选择“使用PyPTO Toolkit打开”。
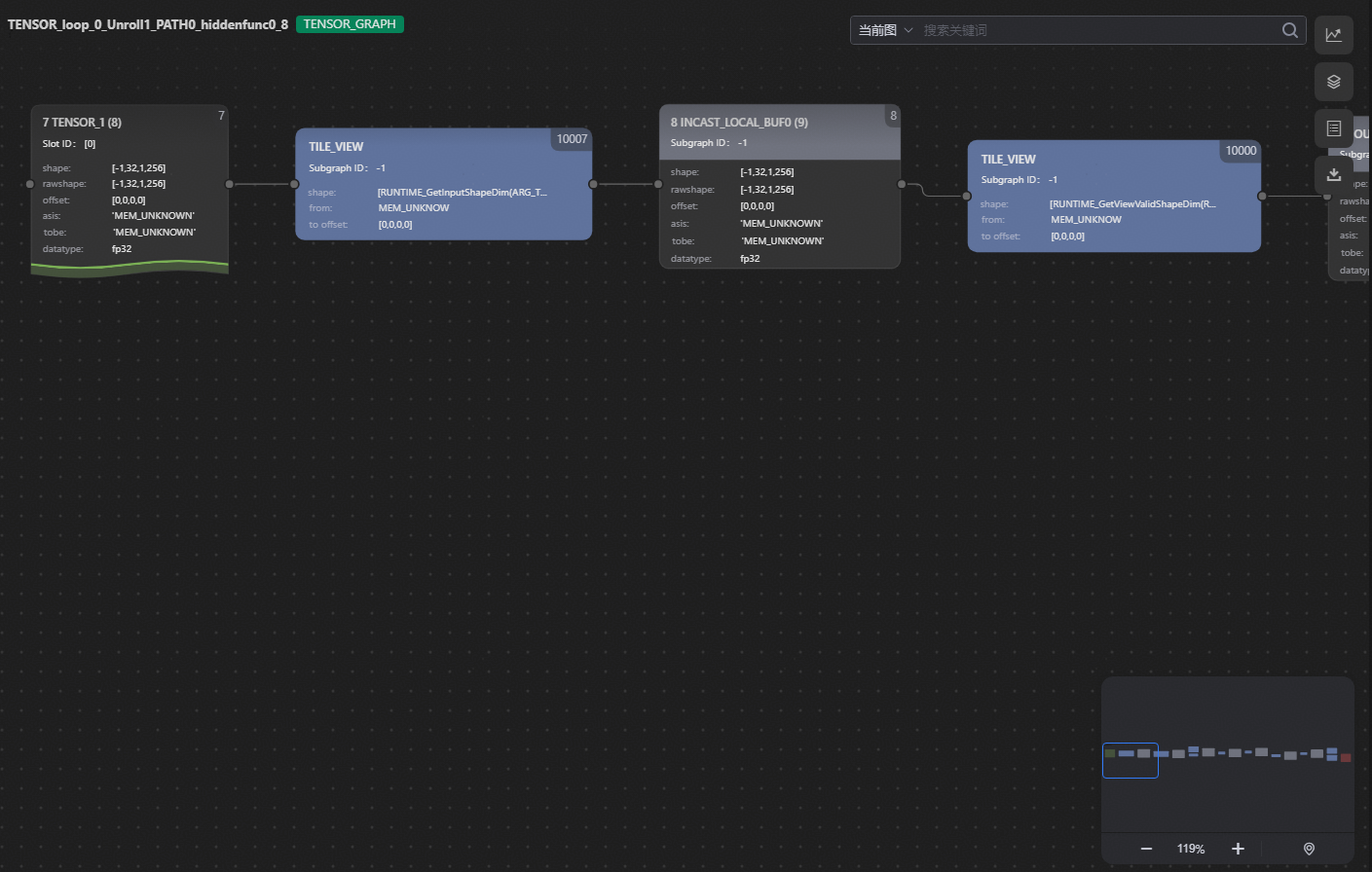
右上角可以看到计算图类型为Tensor Graph,Tensor Graph由Tensor和Operation组成,图中的Tensor Shape和代码定义一致,且没有经过Tile展开。
通过PyPTO Toolkit查看Tile Graph。
右键单击Before_026_SubgraphToFunction_TENSOR_loop_0_Unroll1_PATH0_hiddenfunc0_8.json文件,在弹出的菜单中选择“使用PyPTO Toolkit打开”。
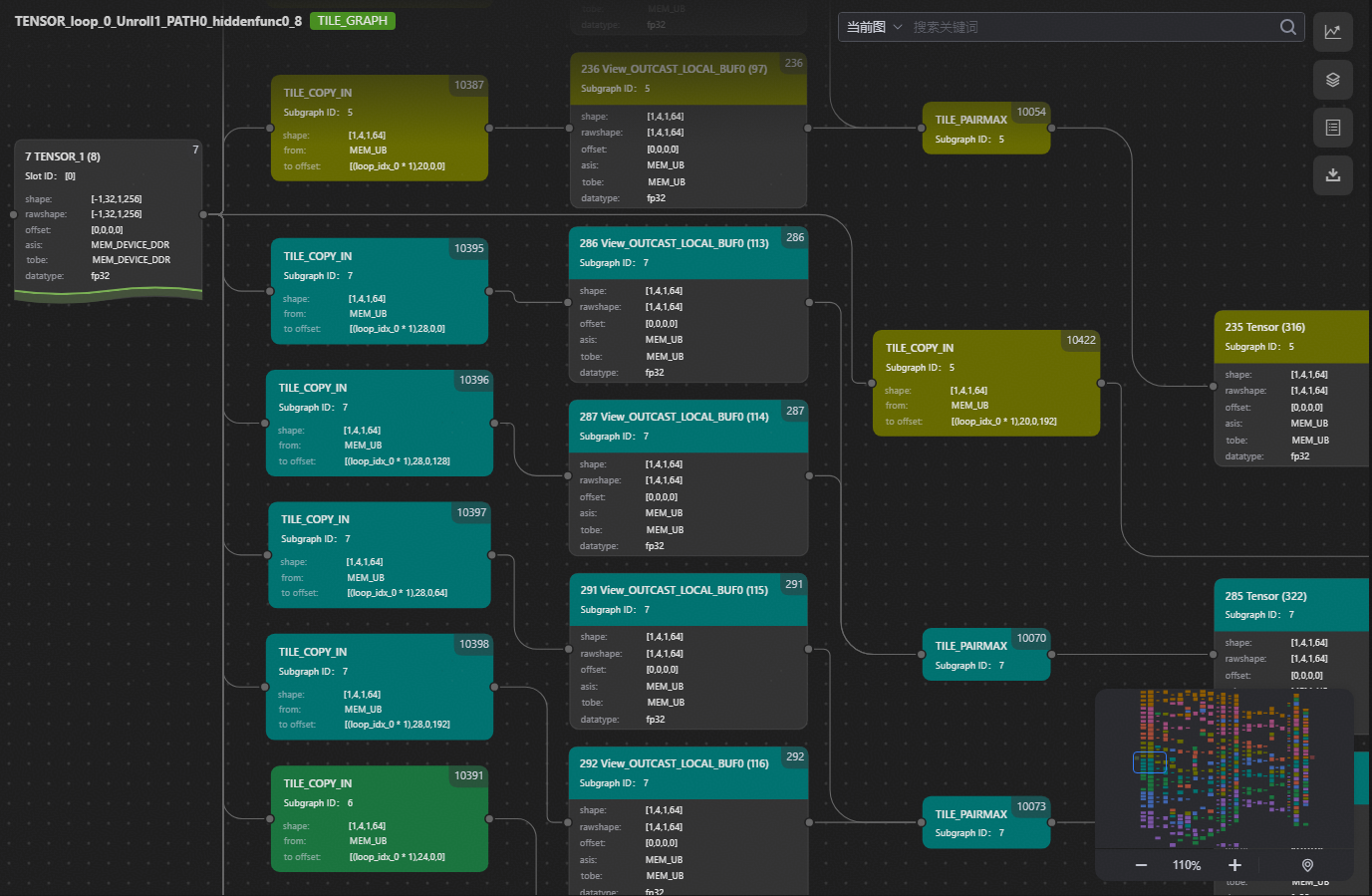
右上角可以看到计算图类型为Tile Graph,相比于Tile展开前,Tile Graph中增加了很多节点,这是因为原Shape为(-1, 32, 1, 256)的Tensor经过Tile展开,切分成Shape为(1, 4 ,1, 64)的Tile。同时,为Tile分配内存层级(对应图中asis-原地址,tobe-目的地址),并自动插入内存搬运节点(对应图中TILE_COPY_IN和TILE_COPY_OUT)。
通过PyPTO Toolkit查看Block Graph。
右键单击After_036_CodegenPreproc_TENSOR_loop_0_Unroll1_PATH0_hiddenfunc0_8_LEAF_program_id_00_15536366383870408930.json文件,在弹出的菜单中选择“使用PyPTO Toolkit打开”。
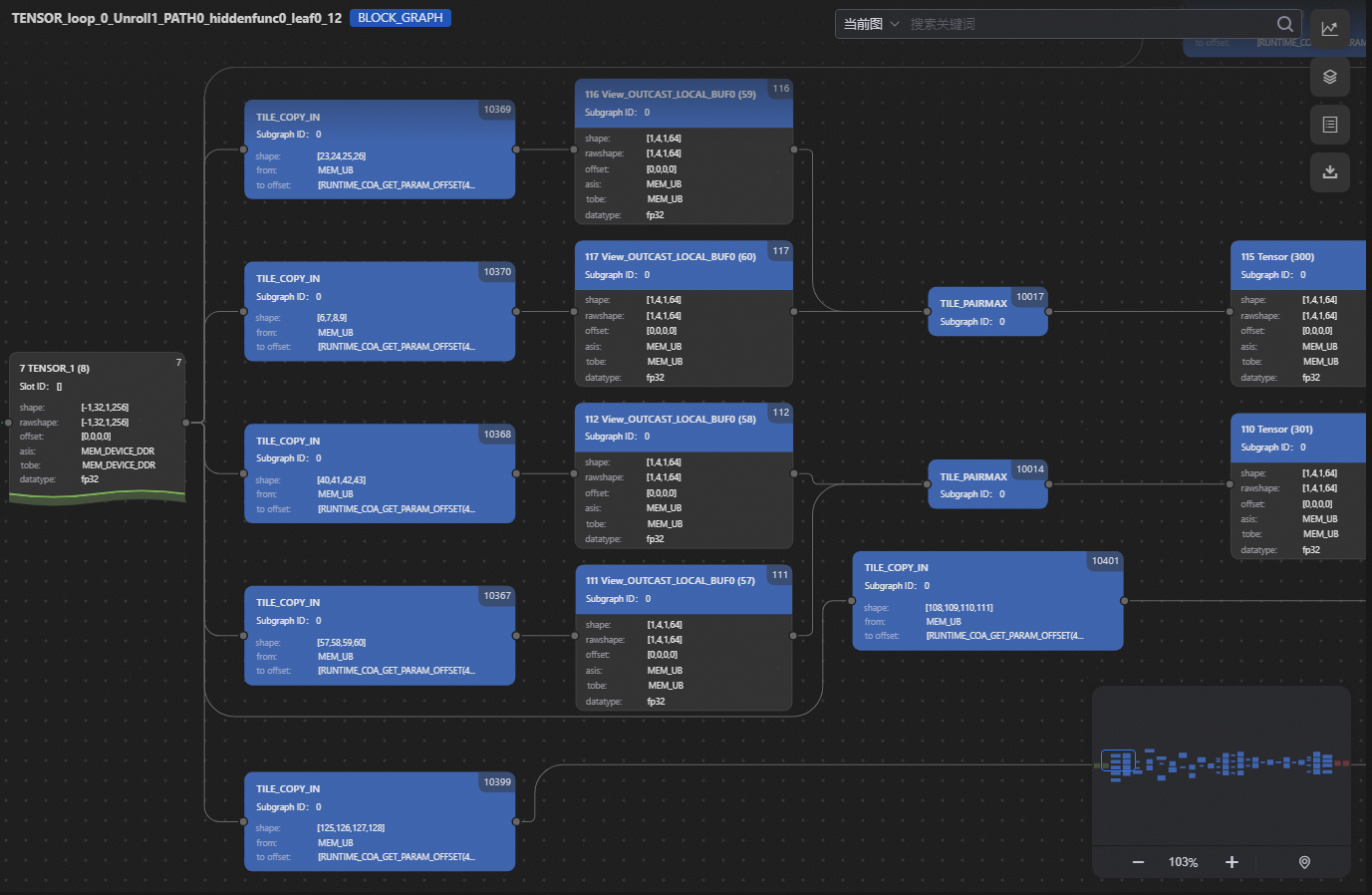
右上角可以看到计算图类型为Block Graph,在Block Graph阶段,Tile Graph被切成若干子图,每一个子图对应一个Block Graph,因此相比Tile Graph,Block Graph的规模大量减少。
当前sample被切分成多个结构相同的子图(简称同构子图),因此Pass_36_CodegenPreproc目录下仅有一个文件名称包含After_036_CodegenPreproc_*_LEAF_*关键字的json文件。
通过PyPTO Toolkit查看Execute Graph。
右键单击After_036_CodegenPreproc_TENSOR_loop_0_Unroll1_PATH0_hiddenfunc0_8_ROOT.json文件,在弹出的菜单中选择“使用PyPTO Toolkit打开”。
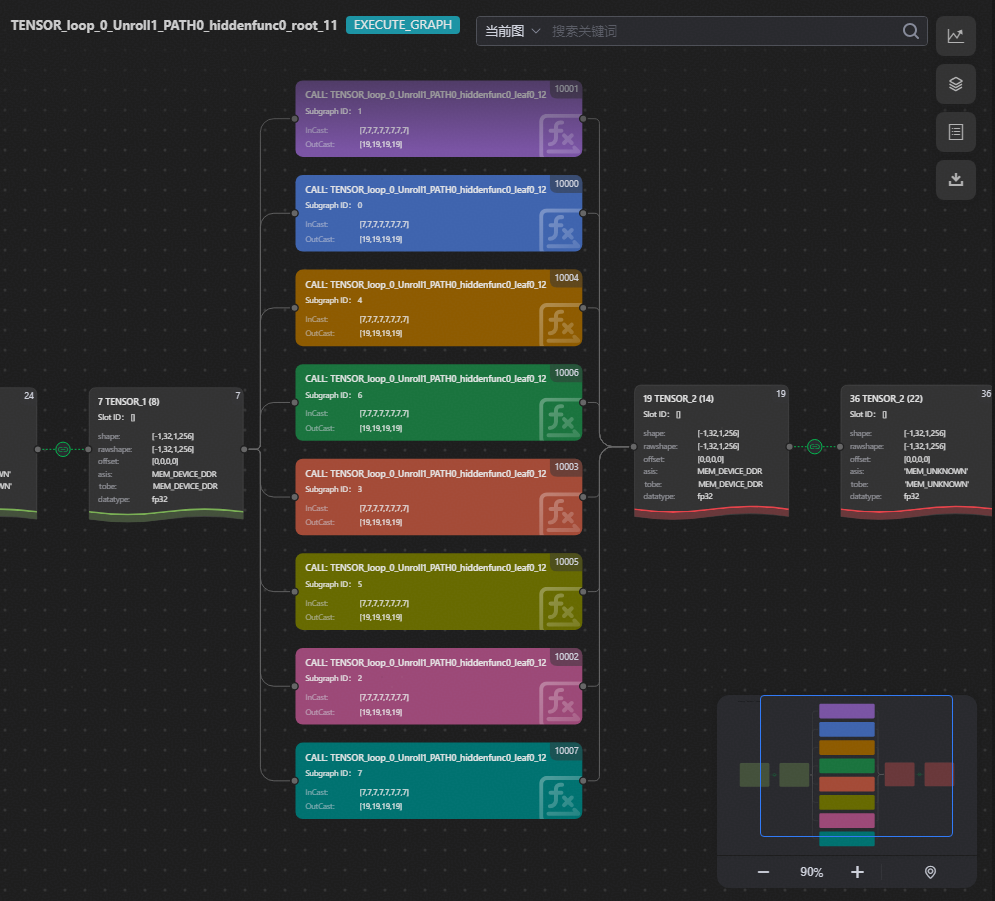
右上角可以看到计算图类型为Execute Graph,Execute Graph中包含Tensor节点和调用节点(带有fx标识,表示对Block Graph进行一次调用),双击调用节点,可以查看对应的Block Graph子图信息,了解具体的执行过程。
CPU仿真调试#
在不具备昇腾设备时,也支持在CPU仿真环境中进行测试体验:
性能仿真:支持用户查看算子的核内流水数据。
精度仿真:支持用户在CPU环境获取算子运算结果(精度仿真依赖CANN软件包)。
若仅需要运行仿真,而且当前环境没有昇腾设备,请勿安装TorchNPU,否则可能运行失败。
运行模式选择逻辑为:
手动指定仿真模式:
在算子代码中显式调用
@pypto.frontend.jit(runtime_options={"run_mode": pypto.RunMode.SIM}),强制启用CPU仿真模式执行算子程序。 pypto先执行性能仿真,性能仿真执行完成后,若检测到CANN软件包,则继续执行精度仿真。自动识别模式(仅支持性能仿真,不支持精度仿真):
未检测到CANN软件包:自动启用仿真模式(无需显式配置)。
检测到CANN软件包:优先使用真实硬件执行,仿真模式不生效。
Atlas A2 训练系列产品/Atlas A2 推理系列产品、Atlas A3 训练系列产品/Atlas A3 推理系列产品#
操作步骤如下:
指定运行参数run_mode。
@pypto.frontend.jit(runtime_options={"run_mode": pypto.RunMode.SIM})
执行算子,自动触发仿真运行。
python examples/00_hello_world/hello_world.py --run_mode=sim
性能仿真执行成功后,在output目录下,生成以下文件信息。
右键单击merged_swimlane.json文件,在弹出的菜单中选择“使用PyPTO Toolkit打开”。
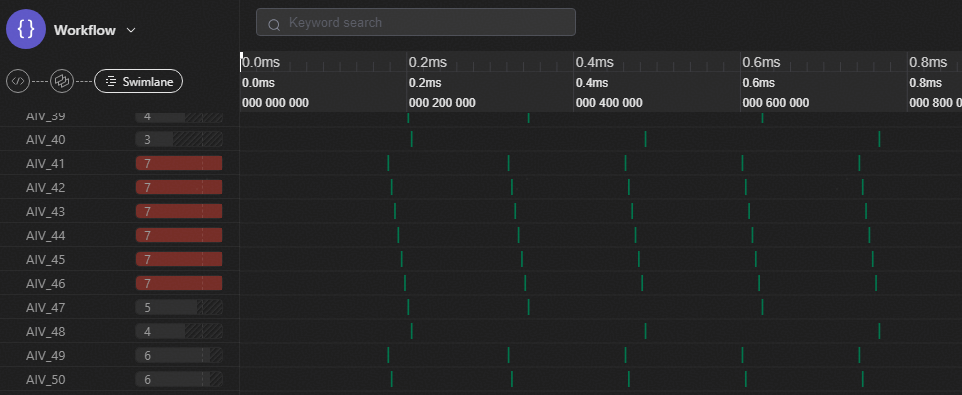
泳道图展示每个核内任务调试情况,包含执行耗时、空闲间隔等,可根据具体情况对算子进行调优,如调整张量的分块形状。
精度仿真与NPU执行一致,执行完成后,会返回运行结果,用户可获取结果并进行处理。
Ascend 950PR/Ascend 950DT#
Ascend 950PR/Ascend 950DT 支持以下两种仿真模式,均通过cannsim record命令启动,开发者可根据调试目的选择:
CostModel:任务级仿真,粒度较粗、速度快但精度较低;输出泳道图(merged_swimlane.json),通过PyPTO Toolkit查看核间任务的调度与并行情况,适用于快速评估算子的任务调度与核间并行度。
CAModel:指令级仿真,粒度较细、精度高但速度慢;输出流水报告(trace_core*.json),通过chrome://tracing查看核内指令的执行细节,适用于分析核内流水、进行精细性能调优。
CostModel#
指定运行参数run_mode。
@pypto.frontend.jit(runtime_options={"run_mode": pypto.RunMode.SIM})
指定tensor分配cpu。
input_data = torch.rand(shape, dtype=torch.float, device='cpu')
执行算子,自动触发仿真运行。
cannsim record 'python3 examples/00_hello_world/hello_world.py --run_mode sim' -s Ascend950 -o output/
性能仿真执行成功后,在output目录下,生成以下文件信息。
右键单击merged_swimlane.json文件,在弹出的菜单中选择“使用PyPTO Toolkit打开”。
泳道图展示每个核内任务调试情况,包含执行耗时、空闲间隔等,可根据具体情况对算子进行调优,如调整张量的分块形状。
精度仿真与NPU执行一致,执行完成后,会返回运行结果,用户可获取结果并进行处理。
CAModel#
指定运行参数run_mode。
@pypto.frontend.jit(runtime_options={"run_mode": pypto.RunMode.SIM})
指定tensor分配cpu。
input_data = torch.rand(shape, dtype=torch.float, device='cpu')
执行算子,自动触发仿真运行。
cannsim record 'export ACCURACY_LEVEL=2 && python3 examples/00_hello_world/hello_world.py --run_mode sim' -s Ascend950 -n 0 -g -o output/
性能仿真执行成功后,在output/cannsim_*/目录下,生成以下文件信息。

执行生成报告命令。
cannsim report -e output/cannsim_*/ -o output/cannsim_*/report --core-id all
执行生成报告命令后,在output/cannsim_*/report目录下,生成以下文件信息。

把图中如trace_core0.json放入chrome://tracing/中,即可得到流水报告。

流水报告展示每个核内指令的执行情况,包含执行耗时、空闲间隔等,可根据具体情况对算子进行调优,如调整张量的分块形状。
精度仿真与NPU执行一致,执行完成后,会返回运行结果,用户可获取结果并进行处理。