GatedDeltaRule算子性能优化案例#
任务与目标#
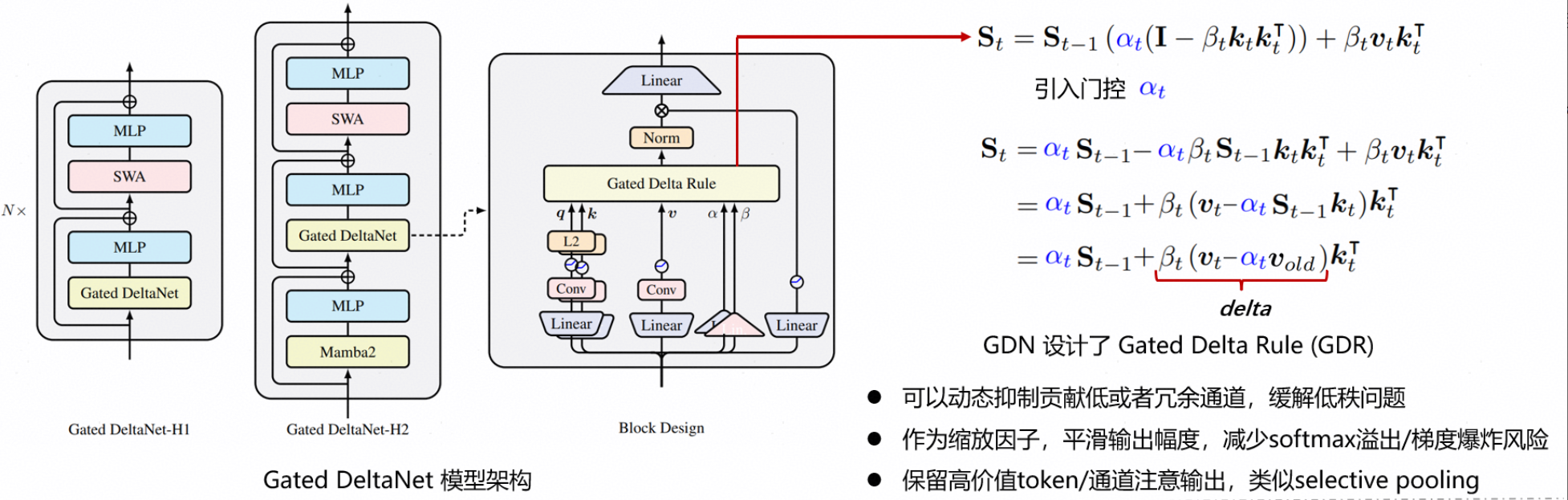
Transformer凭借强大的注意力机制,具备卓越的序列建模能力,在大语言模型领域取得了突破性进展。然而,自注意力模块的计算复杂度随序列的长度成二次方增长,在训练与推理过程中面临巨大的算力挑战。为了缓解这一问题,研究人员提出了线性Transformer替代方案,将核化点积注意力替代传统softmax注意力,将其重构为具有矩阵状态的线性RNN,显著降低了训练与推理阶段的算力需求。 论文Gated Delta Networks: Improving Mamba2 with Delta Rule提出了Gated DeltaNet架构,通过结合门控机制和Delta更新规则,提升线性Transformer在长序列建模和信息检索任务中的表现。
图1 Gated DeltaNet模型架构
算子框架#
@pypto.frontend.jit
def chunk_gated_delta_rule():
# loop b并行
for b_idx in pypto.loop(B):
# loop n并行
for nv_idx in pypto.loop(Nv):
# loop s串行
for s_idx in pypto.loop(0, S, L):
# view
...
# compute
# recurrent_loop前计算逻辑可并行执行
...
# recurrent_loop由于输出state逐chunk更新其计算逻辑必须串行
...
# assemble
...
调优流程#
PyPTO Config配置调优#
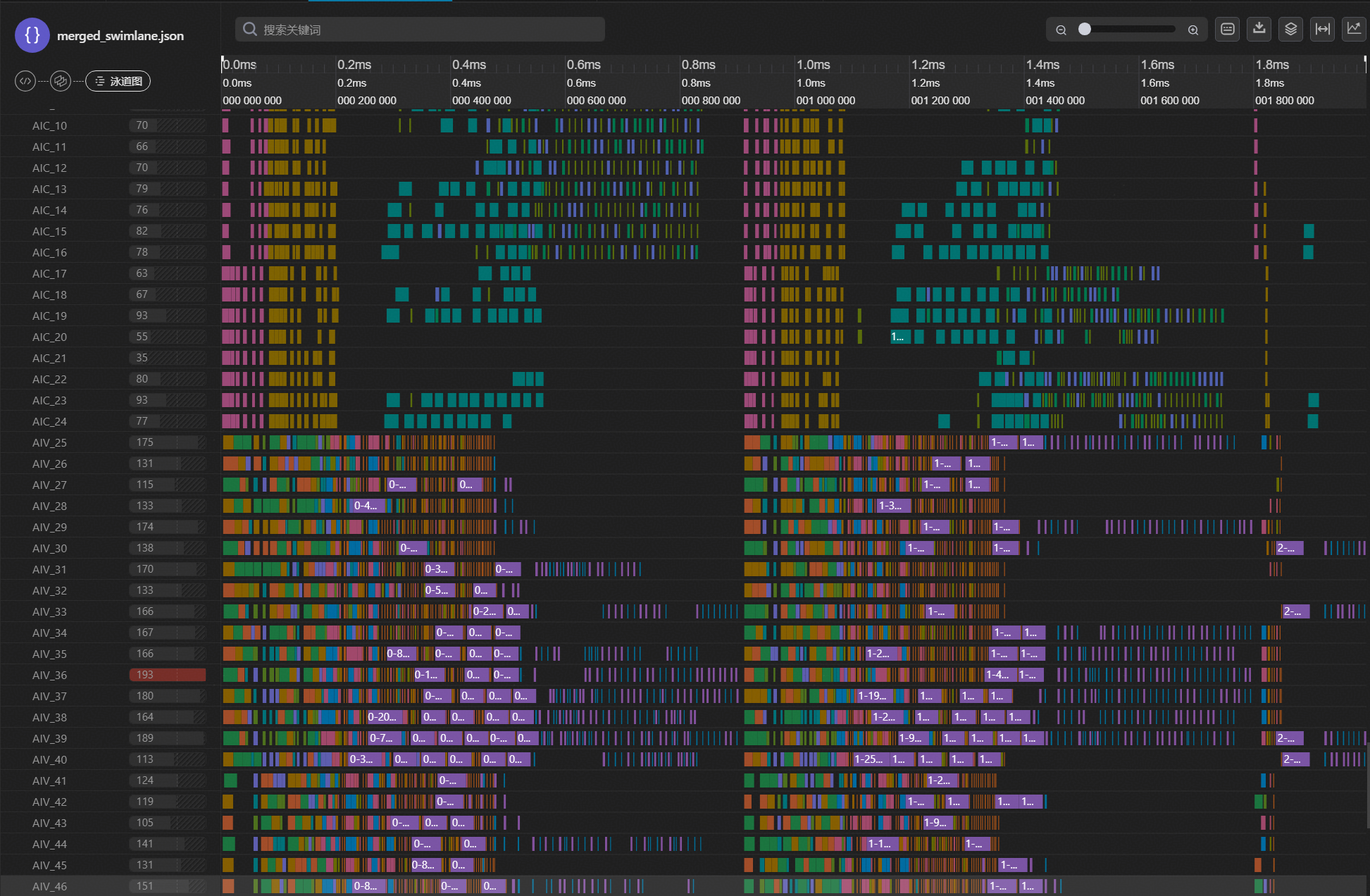
PyPTO中提供了各种Config配置,以便用户针对其特定的融合算子实现,进行深入的自定义优化,如Pass合切图策略调整、Runtime任务调度策略等。其中,与GDN算子性能调优相关性最强的配置为runtime_options中的stitch_function_max_num,其中动态stitch是PyPTO的MPMD架构的关键技术,通过由AICPU基于运行时输入动态决定执行的控制流,并动态计算依赖,将任务stitch组合下发。stitch_function_max_num配置代表machine运行时ctrlflow aicpu里控制首个提交给schedule aicpu处理的device task的计算任务量,通过此值来控制device machine启动头开销的大小,让ctrlflow aicpu和schedule aicpu计算尽快overlap起来。 以下展示泳道图,均为B=2,T=8192,H=4,D=128的数据场景。如图3-1和图3-2所示,分别为stitch_function_max_num设置为32的泳道图和stitch_function_max_num设置为128的泳道图,其设置大小越大,stitch设置较大后任务可以充分并行,性能更好,但workspace也会增加,需要权衡。
图2 stitch_function_max_num设置为32的泳道图
图3 stitch_function_max_num设置为128的泳道图
昇腾亲和的Tile Shape大小调优#
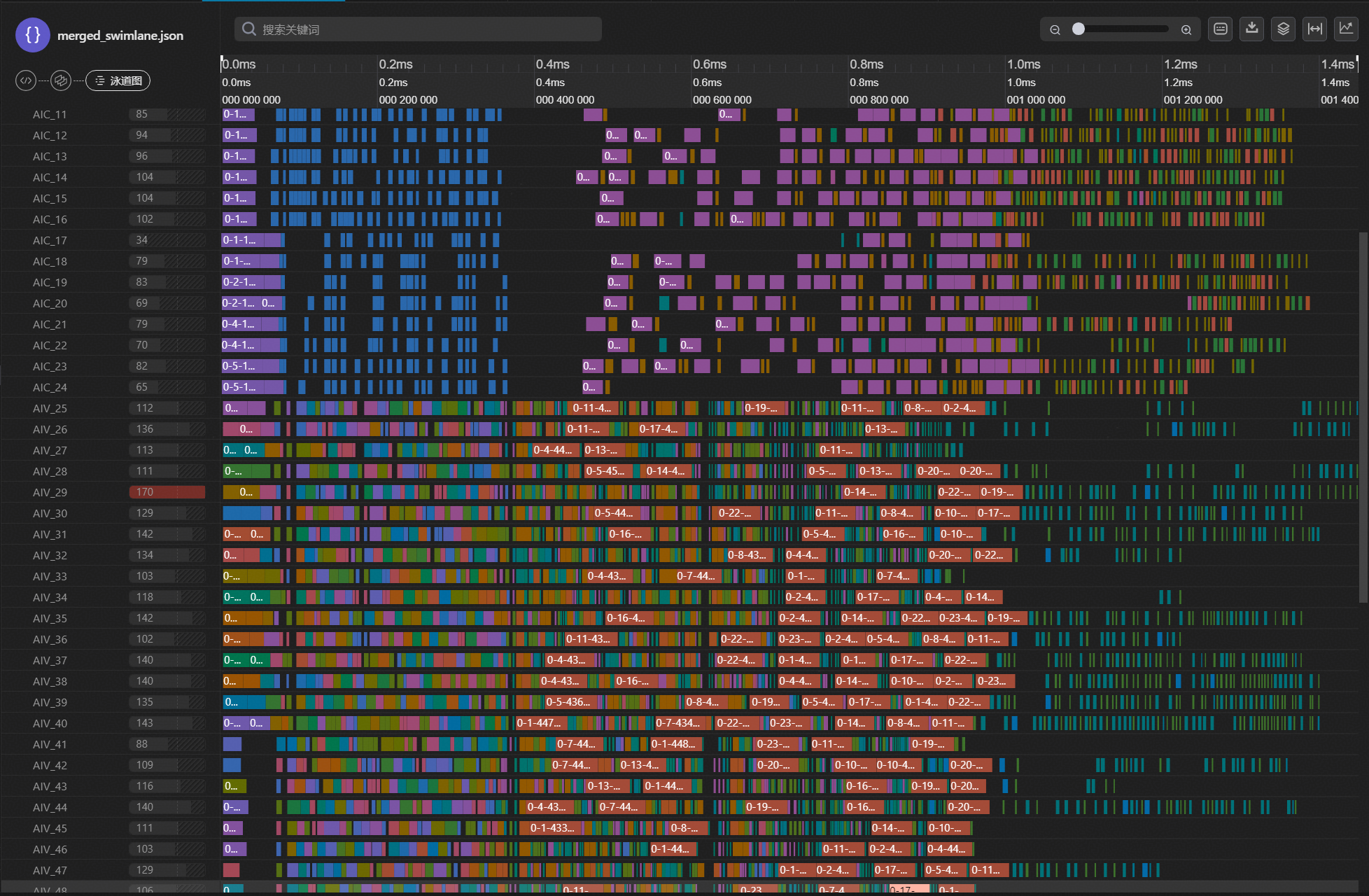
在PyPTO中,所有计算都基于Tile(硬件感知的数据块)进行,充分利用硬件的并行计算能力和内存层次结构。 Tile可以存放在AICore私有缓存(如UB、L1)中,从而显著提升数据访问效率。对于每个OP操作,都可以灵活设置其tile_shape大小,以优化计算负载均衡、内存带宽利用率,并最大化硬件资源的使用效率,以充分利用UB的容量,贴合昇腾架构特性。基于GPU开发的Triton算子通常将分块大小设置为64,此时参与计算的Tile块shape大小为[64, 128],当dtype为FP32时,可计算出其数据量大小为32KB,而通常昇腾NPU的UB192KB时,合适的Tile块大小选取为16-64KB,将chunksize大小调整为128后,则数据量可增大至64KB,更符合尽量一次搬运较大的数据块的昇腾算子开发策略,大大减少数据搬运带来的性能开销,并充分发挥硬件的并行计算能力。此外,由于GDN算子存在的chunk循环更新算法特性,一次对更大chunksize的数据进行处理,可减少其串行循环更新次数,缓解在PyPTO现有MPMD调度策略下造成的串行计算逻辑难以充分并行用满核的性能问题。 如图3-3所示,与图3-2相比,为chunk_size从64优化为128,TileShape从[64, 128]优化为[128, 128]的泳道图,Tile块数据大小更亲和昇腾NPU硬件存储大小,可减少Loop循环次数,减少root function个数以及task任务数量,stitch绑定下发的任务不变的前提下(stitch_function_max_num=128),减少了stitch数量,本质上是减少搬运开销,提升计算效率。
图4 chunk_size为128,TileShape为[128, 128]的泳道图
PyPTO Loop方式及合图展开优化#
动态Loop调整为静态Loop#
PyPTO采用PTO(Parallel Tensor/Tile Operation)编程范式,以基于Tile的编程模型为核心设计理念,通过多层次的计算图表达,将用户通过API构建的AI模型从高层次的Tensor计算图逐步编译成硬件指令,最终生成可在目标平台上高效执行的代码,并由设备侧以MPMD(Multiple Program Multiple Data)方式自动调度执行,其中理解PyPTO Loop循环以及合切图逻辑是对其前端表达的进一步深入认知。首先,PyPTO中的Loop循环主要是为了处理动态shape,在整网中的batch_size、seq_length等参数往往是动态的,而Tile切块大小往往是固定的,而PyPTO框架将提前标记好的动态轴,通过在编译阶段使用SymbolicScalar组成的表达式来翻译为CCE代码,随后在Machine层去解析表达式的具体大小,进而动态的处理不同Shape下的上板运行状态,这样的处理方式使得其可以大大减少编译构图的重复性时间,使得不同动态shape输入共用同一套前端表达与构图IR。而在GDN算子中,其中的求逆模块则是对Tile块进行逐行的计算更新,在不考虑尾块的场景(尾块也可做Padding),其逐行Loop的次数是固定的,而PyPTO的Loop实际次数是会占用root function,即一次Stitch能够绑定下发的任务数,那么在编程范式上,求逆模块更适合使用Python的静态Loop方式,牺牲了一定的编译性能,但可大大减少需要大量重复计算的求逆模块在使用动态Loop时带来的运行态开销。
# row_num是一个静态值
# 原动态Loop方式
for i in pypto.loop(2, row_num, 1):
# 求逆逐行更新
# 修改为静态Loop方式
for i in range(2, row_num, 1):
# 求逆逐行更新
合切图优化#
PyPTO的计算图由Tensor数据节点与Operation节点组成,经过逐层Pass优化,将用户前端定义的Tensor Graph计算图最终转换为Execution Graph执行图,并最终翻译为CCE可执行代码,Execute Graph整合计算子图信息,包含了各自的依赖关系和调度信息,定义了Tile在AIC/AIV的具体Operation组合,不同的合切图优化方式对性能的影响极大,通常Pass会提供泛化性的优化策略,帮助用户获取到较好的开销性能,但如果需要对Tile块的具体计算流进行控制,则需要借助计算图的DFX能力,可视化的检查其是否符合预期,如图3-4所示,为B=1,T=128,H=1下初始开箱的泳道图,发现其存在较多的耗时极短的碎块以及异常的耗时较长的执行图,通过对计算图计算流的检查对比后,发现PyPTO框架本身存在一定的合切图功能问题,导致如求逆模块未正确的按前端表达进行合切图,后续与框架开发人员交流讨论后,便可将问题解决,如图3-5所示,为B=1,T=128,H=1下合切图手动调整后的泳道图,此时的计算逻辑图前端表达高度一致,如求逆模块为8个16*16Tile块的并行逐行更新的同构子图。PyPTO向用户提供了一定程度的可视化DFX能力,其能够帮助用户更简单直观的了解到具体的运行态计算流,进而发现问题、解决问题。
图5 B=1,T=128,H=1下初始开箱的泳道图
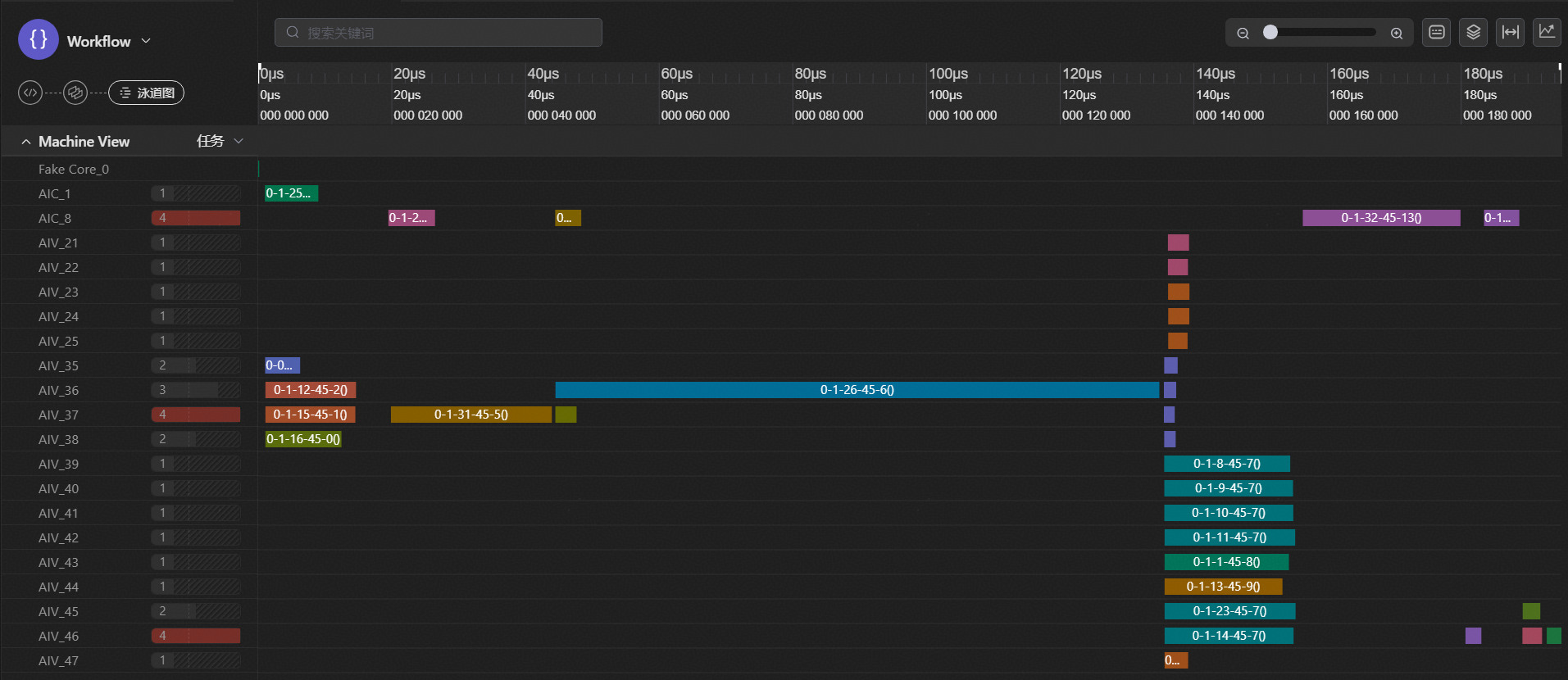
图6 B=1,T=128,H=1下合切图手动调整后的泳道图
unroll_list优化#
在了解了root function、stitch等运行态概念后,从泳道图中,我们可以发现GDN算子的并行计算逻辑加串行计算逻辑的算法构成,由于PyPTO框架目前的Stitch策略及调度策略情况,导致了其在S较大的情况下,逐chunk的state更新难以用满核,PyPTO则是提供了unroll_list的能力,将最内层的Loop图合并,展开次数为n时,循环步长会变成step*n,每次迭代会执行n次循环体,进而提高外层BN的并行计算能力,本质上也是减少Loop循环次数,减少root function个数以及task任务数量,stitch绑定下发的任务不变的前提下(stitch_function_max_num=128),减少了stitch的数量。如图3-6所示,与图3-3相比,为在Loop S中设置unroll_list=[16]时的泳道图。
# 原始
for s_idx in pypto.loop(0, s, l, name="LOOP_S_TND", idx_name="s_idx"):
# 设置unroll_list=[16]
for s_idx in pypto.loop(0, s, l, name="LOOP_S_TND", idx_name="s_idx", unroll_list=[16]):
图7 设置unroll_list=[16]的泳道图
基于DFX的深度性能调优#
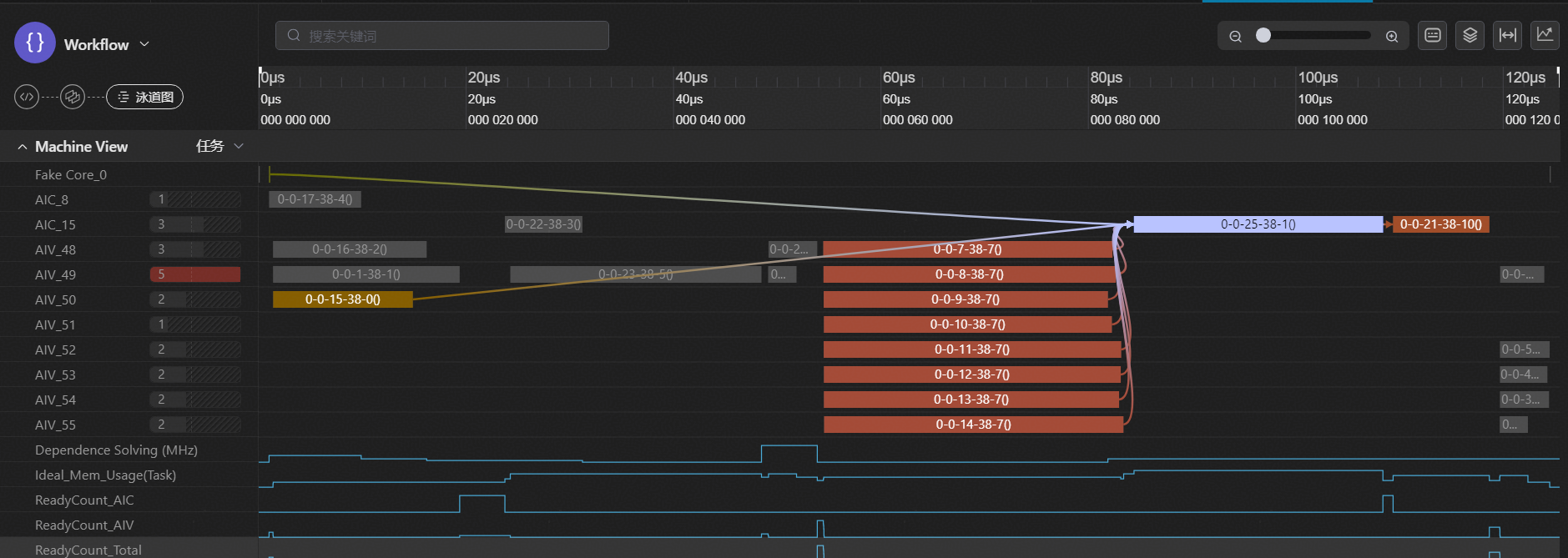
如图3-8所示,在GDN初始开箱实现中,我们对[128, 128]的Tile块求逆实现,采取了先对8个[16, 16]的块进行求逆算法,其在较小shape场景下的并行计算能力较强,但见图3-9所示,在较大数据量(AIV核已充分用满的情况下),计算效率并不高,由计算图、泳道图提供的DFX能力上,我们提出了将8个[16, 16]的块由尾轴concat为2个[16, 64]的块进行计算的尾轴合并优化方案,来减少搬运开销,并提升计算效率。但是,得到的穿刺收益并不如预期,见图3-7所示,仅从822 us提升至262 us,并不符合预期收益。而对计算图中的计算流进行检查后,发现其存在较多的拷贝拷出开销,见图3-8中的绿色与红色节点。
图8 求逆尾轴合并优化初版穿刺方案的泳道图
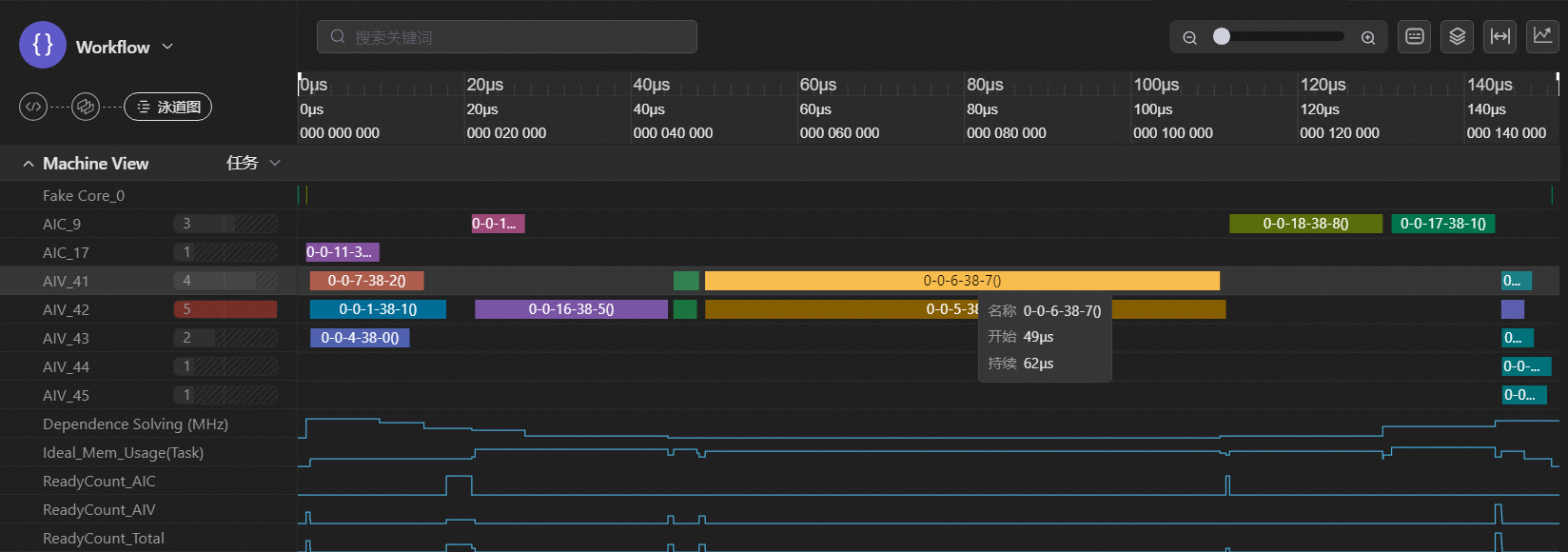
图9 求逆尾轴合并优化初版穿刺方案的计算图(绿节点代表拷入,红节点代表拷出)
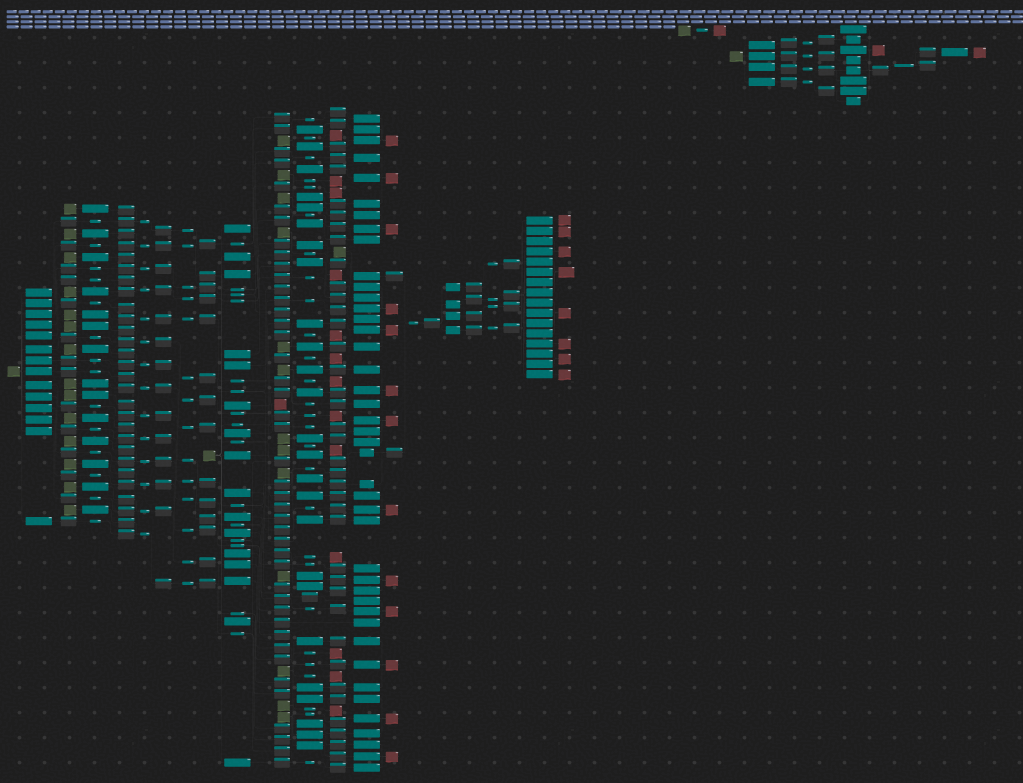
根据计算图的计算流与前端代码对比,发现是由于逐行更新的矩阵频繁的在UB上搬入搬出导致,但预期上其是可以常驻内存,便可就此进行深入的优化,见图3-9,为优化后的计算图,只在计算流的最左侧进行数据拷入,在右侧进行数据拷出,符合预期。
图10 求逆尾轴合并优化穿刺方案的计算图

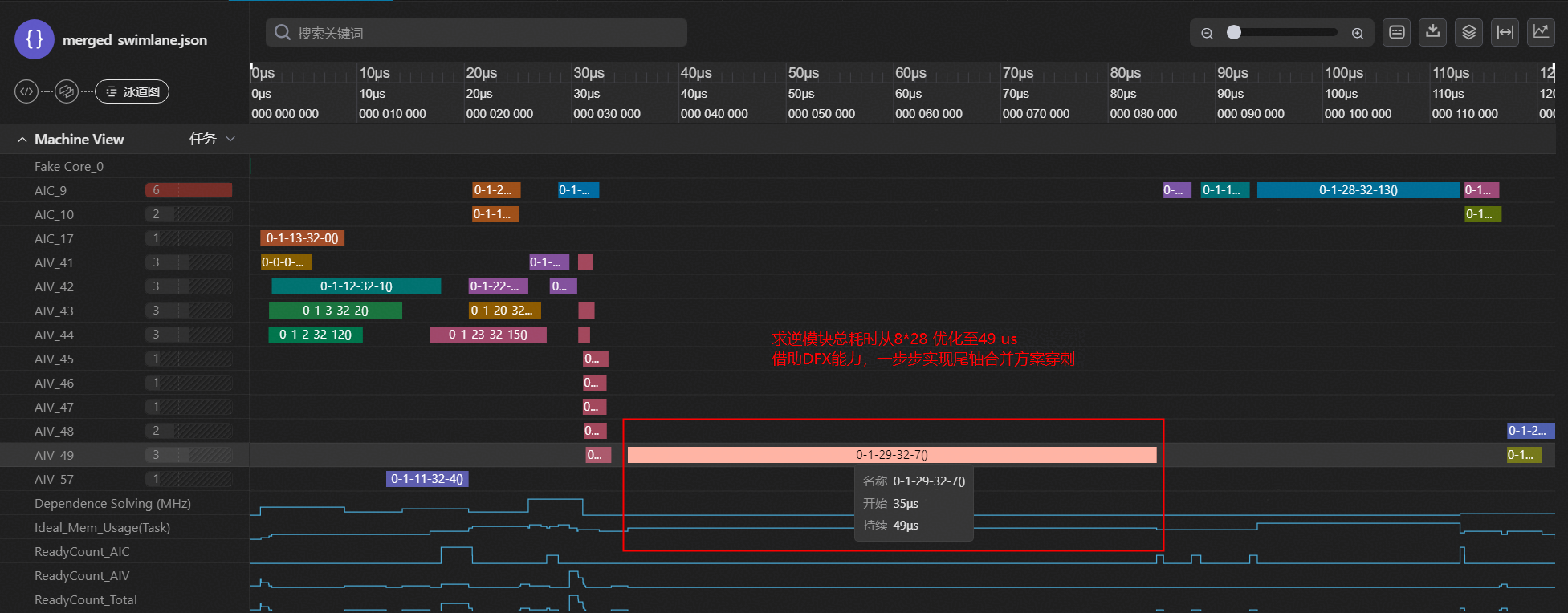
最后,再将尾轴合并方案优化为concat为一个[16, 128]的块进行逐行求逆,得到的最终求逆尾轴合并优化穿刺方案的泳道图,见图3-10,求逆模块耗时从8*28 us提升至49 us。
图10 求逆尾轴合并优化最终穿刺方案的泳道图