QuantIndexerProlog算子性能优化案例#
任务与目标#
在DeepSeekV3.2-Exp网络中,引入了Indexer模块。该模块的前半段计算,称之为IndexerProlog计算,其量化版本的计算流如下:
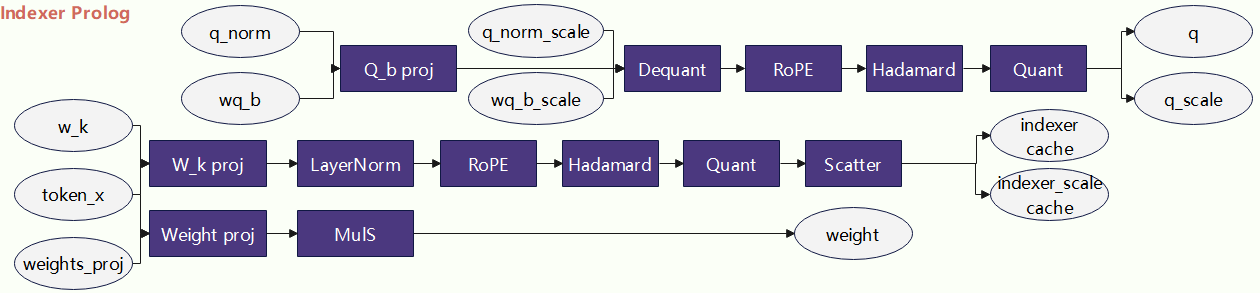
该算子呈现如下特点:
该计算包括了Indexer Q, Indexer Cache和Indexer Weight三个部分,三个部分互相独立,且每个部分串行执行。
三条独立的计算流中,Indexer Q的耗时最长,可以掩盖Indexer Cache和Indexer Weight。
在典型场景(Batch=4,MTP1,Kv Cache长度64k)下,计算量较小,并不会打满所有核进行计算,性能瓶颈在搬运上。
分析主要瓶颈点#
调通精度后,得到了初版性能,也称之为开箱性能,其开箱性能如下:

从开箱性能泳道图上,可以观察到有如下的性能优化点:
Vector任务既多又稀疏,执行子图中存在大量气泡。问题表现为反量化和RoPE的计算未能合并到同一子图中,导致任务数量增加,加大了调度负担,并产生了调度空隙。根本原因是TileShape设置不合理。
Cube计算耗时长,通过调整TileShape,以提升Cube性能;
L1 Reuse尚未开启,部分可以合并的子图未进行合并,导致任务数增多,同时会导致右矩阵存在大量重复搬运;而在典型场景下,通常是搬运bound;若能减少搬运量,便能提升性能;
主要调优流程#
Tile块的调整:经过观察,在反量化和RoPE计算片段,任务数量多,且并没有合并到一个同构子图内;若能达到预期的Vector计算集中到一个同构子图,就能避免冗余的搬运消除;通过调整相关计算中的Tile块,使得相关计算中的Tile块保持一致,这样pass就会把相关计算切到同样一个同构子图内;经此优化后,性能提升至76us,泳道图如下:

Cube Tile块的调整:初始的Tile块为([128, 128], [128, 128], [128, 128]),通常来说会得到一个不错的性能;但由于该算子的实现中,m=8,我们可以设置更为合适的Tile块得到更优的性能,譬如m轴切成16,k轴切大为512/1024,n轴切成64/32,经优化后性能达到56us,泳道图如下:

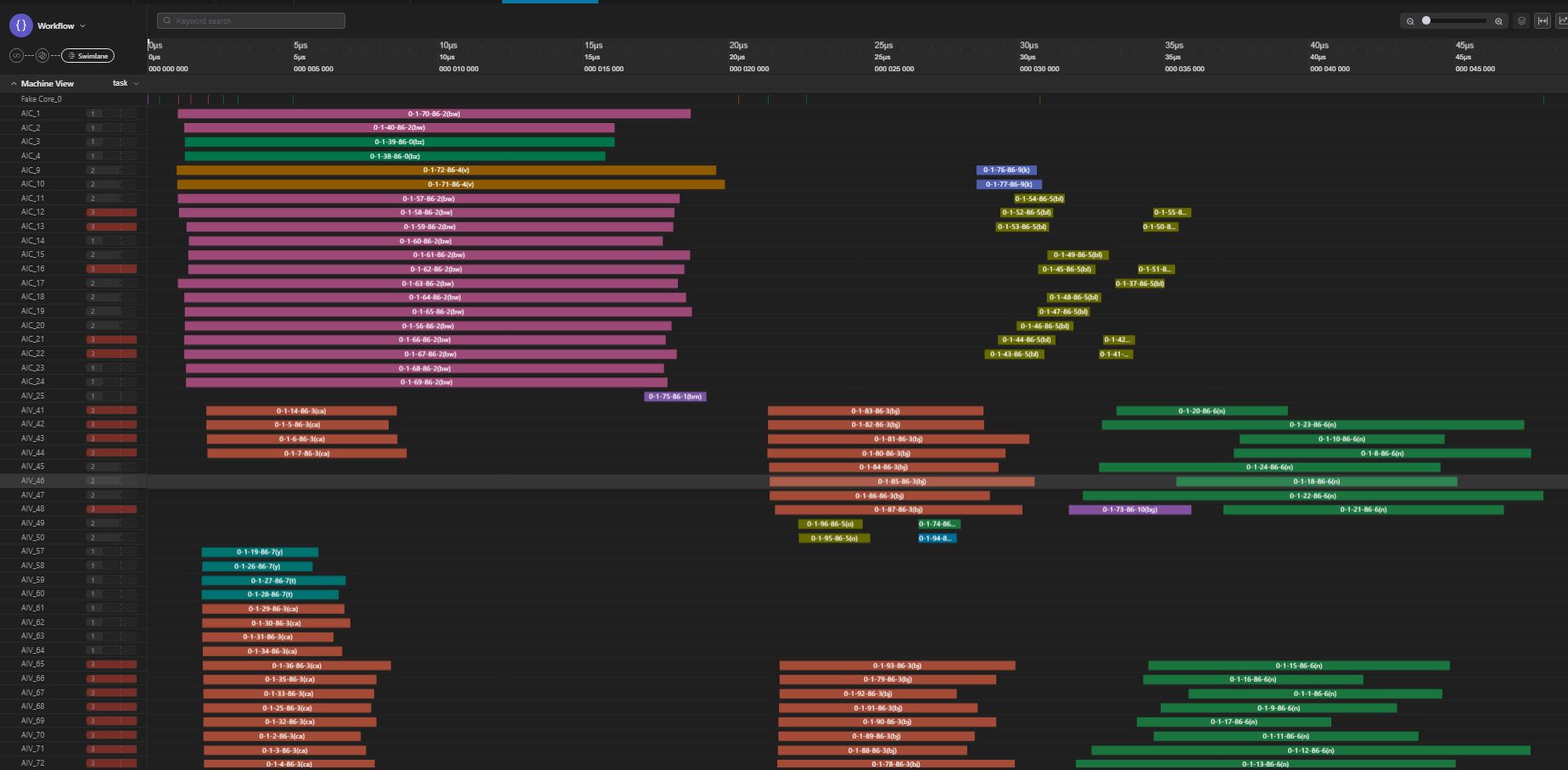
Q计算的Cube任务数量过多,从而导致右矩阵的重复搬运,所以我们开启L1Reuse,使任务合并,减少冗余搬运,经优化后性能达到49us,泳道图如下:
获取完整样例#
实现的example代码位于:lightning_indexer_prolog_quant.py。该文件主要展示了QuantIndexerProlog的具体实现。
QuantIndexerProlog算子在典型场景(Batch=4,MTP1,Kv Cache长度64k),可以运行如下实例脚本执行:
python3 models/deepseek_v32_exp/testdsv32_lightning_indexer_prolog_quant.py
该脚本提供了丰富的测试用例,对于不同场景,用户可以根据需要修改脚本执行不同的用例。