性能调优#
简介#
在融合算子的开发过程中,算子性能优化通常难度极高。本章旨在介绍如何利用PyPTO Toolkit可视化工具,帮助开发者在无需深入了解硬件实现细节的情况下,完成高性能融合算子的编写。
整体流程#
在完成精度调试后,开发者可以利用PyPTO Toolkit查看对应算子的泳道图,泳道图用于直观展示计算图的实际调度与执行过程,清晰呈现任务的执行顺序和耗时信息。基于此,开发者可以得到所编写算子的初版性能,亦可称之为开箱性能。
通过观察泳道图,开发者可以观察到当前算子实现的性能瓶颈点。在观察到瓶颈点后,通过调整Tiling配置和采用不同的计算图编译策略,得到新实现下的算子泳道图,进行进一步地调整,逐步提升算子性能,实现Man-In-The-Loop(人工参与的优化流程)的调优。
性能调优工具#
采集泳道图数据#
当前支持两种并列采集方式:图执行阶段泳道图采集与AI CPU/AI Core联合采集。两种方式可分别单独开启,互不干扰;也可同时开启。若同时开启,可在泳道图中同时观察同一时间轴上的AI CPU与AI Core Profiling数据。
方式一:图执行阶段泳道图采集(runtime_debug_mode)#
适用场景:用于常规性能调优,重点关注子图执行顺序、任务耗时分布、AI Core端到端耗时与AI Core利用率。
通过给
@pypto.frontend.jit装饰器的入参debug_options配置图执行阶段调试开关,启动性能数据采集:@pypto.frontend.jit( debug_options={"runtime_debug_mode": 1} )
执行用例:
python3 examples/02_intermediate/operators/softmax/softmax.py采集结果输出到当前工作目录
output/output_时间戳下(详见“采集结果文件说明”)。
方式二:AI CPU/AI Core联合采集(DUMP_DEVICE_PERF)#
适用场景:用于分析AI CPU调度与AI Core执行的协同关系,定位首任务启动慢、调度等待等问题。
限制说明:
该工具最多支持200轮数据采集和打屏,超出部分将被截断。
当前只支持采集20次devTask构建的数据。当devTask构建次数(与
stitch_function_max_num配置相关,每次stitch对应一次devTask构建)超过20次时,超出部分的perf数据将被截断,并在日志中出现如下告警提示:Dev task num larger than: 20, the excess part will not be recorded
通过环境变量使能:
export DUMP_DEVICE_PERF=true
执行用例:
python3 examples/02_intermediate/operators/softmax/softmax.py采集结果输出到当前工作目录
output/output_时间戳下(详见“采集结果文件说明”)。待数据全部落盘后,手动执行analyze命令查看AI CPU/AI Core数据汇总表:
python tools/scripts/machine_perf_trace.py analyze output/output_<时间戳>/machine_trace_perf_data_0.json
采集结果文件说明和参数含义解释#
关于采集结果文件的详细说明和IDE参数含义解释,请参阅Machine的Troubleshooting(故障诊断)手册:
查看泳道图数据#
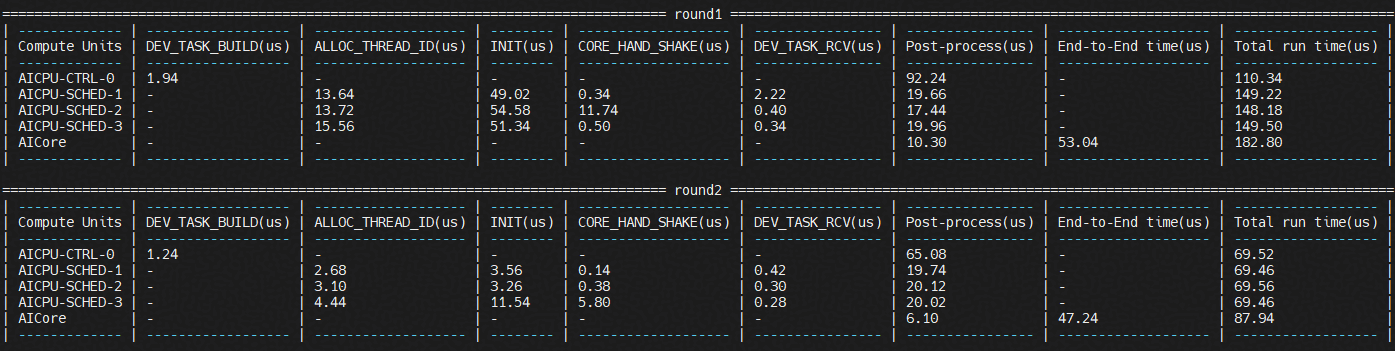
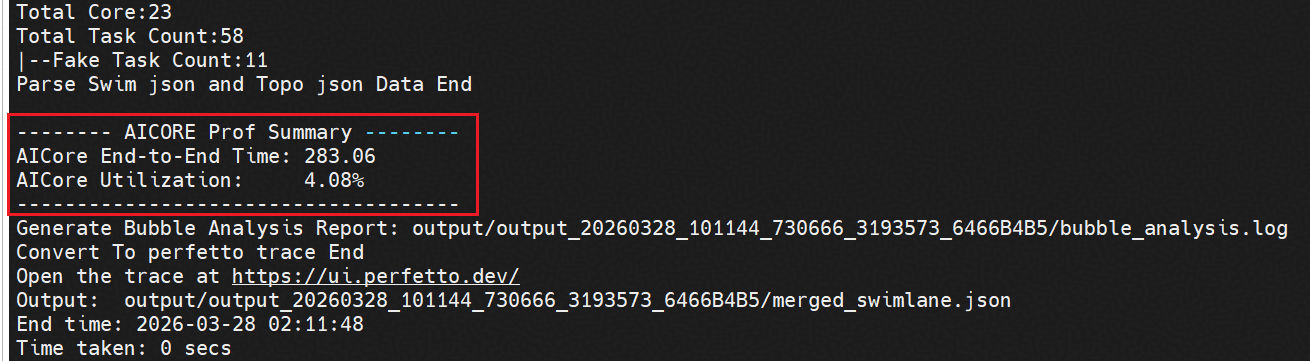
通过终端查看AI Core执行端到端耗时以及AI Core利用率:
图1 查看AI Core Perf信息
通过PyPTO Toolkit插件查看泳道图。
右键单击对应JSON文件,在弹出的菜单中选择“使用PyPTO Toolkit打开”。
图2 查看泳道图
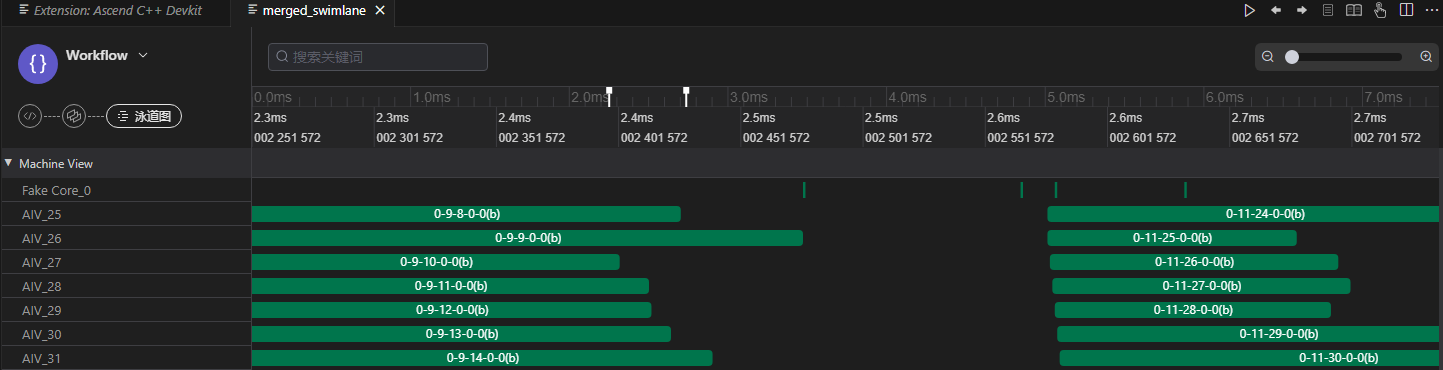
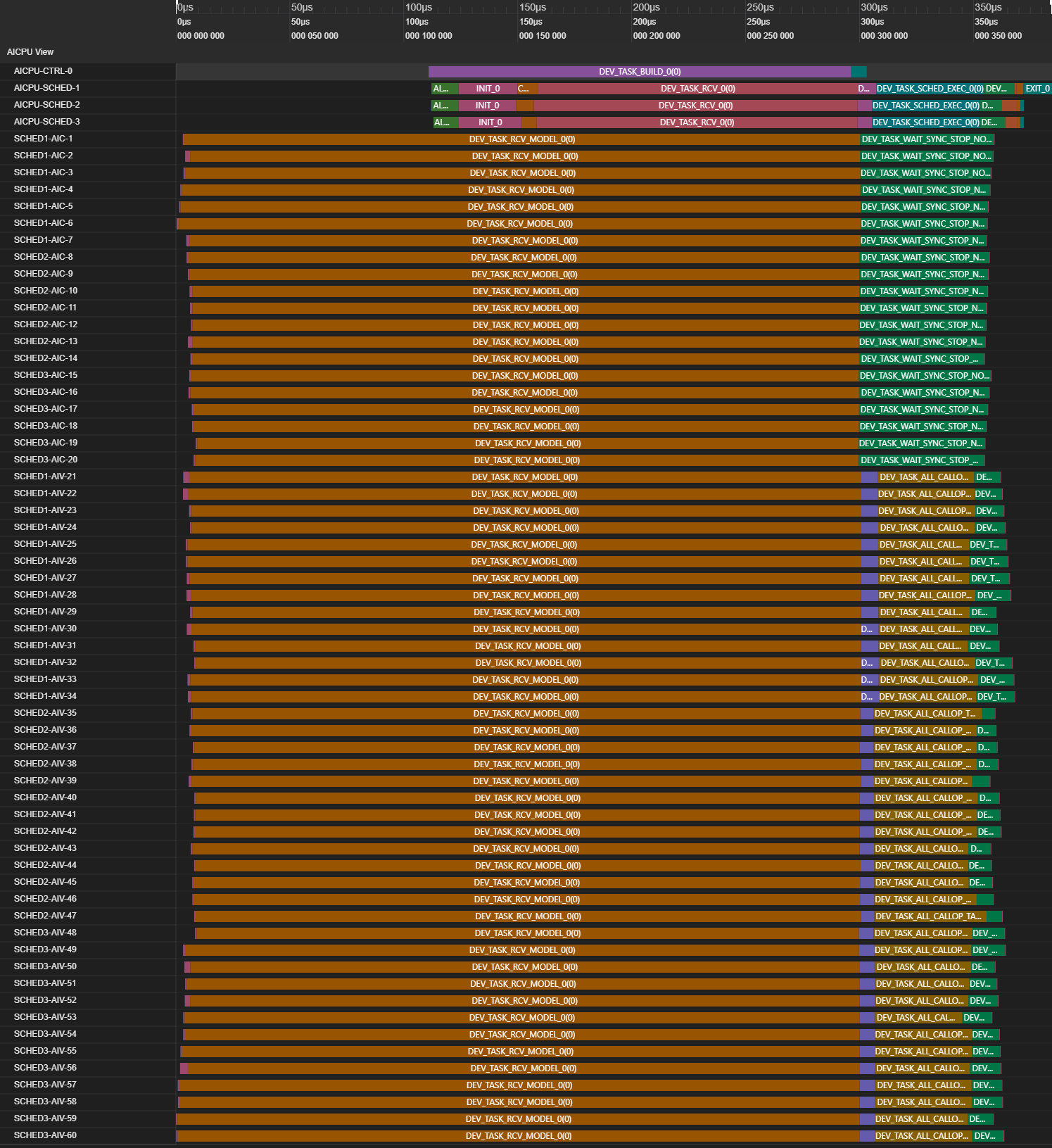
图中展示了任务的执行顺序和耗时信息,帮助开发者分析性能瓶颈。
采集PMU数据#
PMU(Performance Monitoring Unit)是现代处理器中关键的硬件模块,专门用于监控和分析处理器的运行性能。PMU内部有多个可编程计数器,每个计数器可监控一种或多种事件。
步骤1:选择采集模式
通过环境变量选择采集模式:
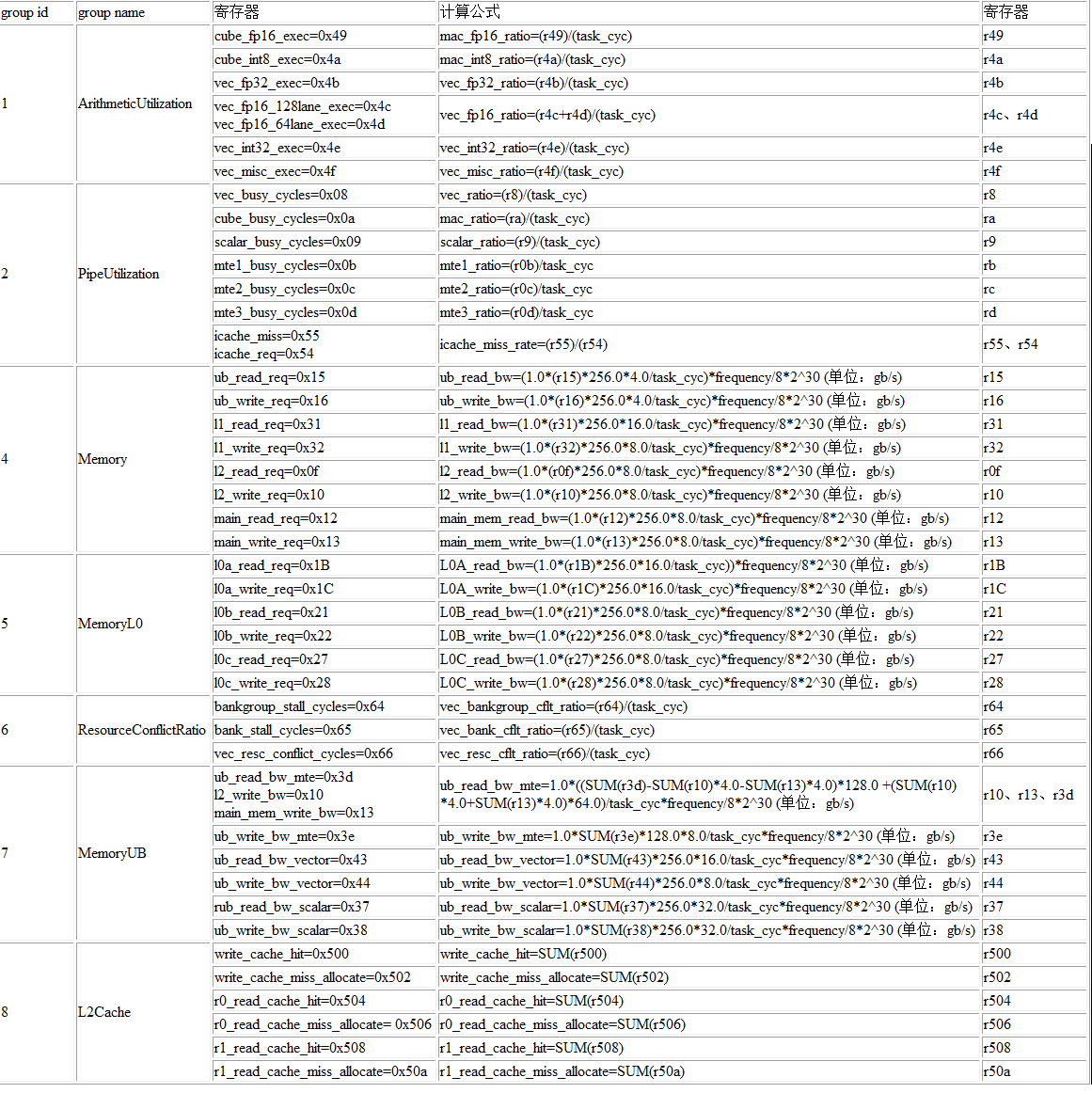
export PYPTO_PROF_PMU_EVENT_TYPE=<group_id>
其中group_id取值范围为[1, 2, 4, 5, 6, 7, 8],默认值为2。PMU支持的模式如下:
步骤2:数据采集
适配编译宏后,通过msprof命令采集PMU数据:
msprof --task-time=l3 [--output=<数据存放路径>] python xxx.py
其中:
l3:开启PMU采集开关--output:指定PROF产物的输出路径,默认落盘在项目根目录下
步骤3:数据解析
PMU数据采集完成后,会落盘在output/PROF*/device_*/data/目录下。根据所选的PYPTO_PROF_PMU_EVENT_TYPE,执行解析脚本:
python tools/profiling/tilefwk_pmu_to_csv.py -p PROF_xxx/device_x/data -pe=$PYPTO_PROF_PMU_EVENT_TYPE --arch [dav_2201, dav_3510]
解析完成后,会在项目根目录下生成tilefwk_prof_pmu.csv文件。
PMU Trace#
PMU Trace用于核内流水分析,是算子深度性能调优的重要工具。开启该能力后,开发者可以直观地观察kernel在AI Core上执行时,各硬件流水线(如MTE2、MTE3、Vector、Cube等)的时序排布与重叠情况。通过分析流水排布,可以识别搬运与计算之间的空闲等待、判断各流水线的利用率是否充分,从而有针对性地调整Tiling配置或计算编排策略,提升算子性能。
限制说明:
产品支持情况:
Ascend 950PR/Ascend 950DT:支持
Atlas A3 训练系列产品/Atlas A3 推理系列产品:不支持
Atlas A2 训练系列产品/Atlas A2 推理系列产品:不支持
当前仅支持单算子采集,不支持整网场景。
当前最多只能采集6个核的数据。
开启PMU Trace#
通过codegen_options中的enable_pmu_trace参数开启。开启后,codegen会在每个leaf function对应CCE代码的首尾插入bisheng::cce::mark_stamp打点,并为其分配PMU ID,用于在核内流水中定位对应kernel。
PMU ID生成规则
PMU ID由CodeGenCloudNPU::GenPMUId()生成(codegen_cloudnpu.cpp),用于标识不同kernel函数。
生成方式:PMU ID = [主块标记] + funcHash 后三位,再对4096取模后作为stamp值。
组成部分 |
规则 |
示例 |
|---|---|---|
主块标记 |
|
主块: |
funcHash 后三位 |
取 |
|
约束:bisheng编译器stamp值上限为4096。为区分主块与尾块,当前仅使用funcHash后三位;子图数量超过约1000时,跨kernel的PMU ID可能重复。
支持两种配置方式:
方式一:在@pypto.frontend.jit装饰器中配置
@pypto.frontend.jit(
codegen_options={"enable_pmu_trace": True}
)
方式二:通过set_codegen_options接口配置
pypto.set_codegen_options(enable_pmu_trace=True)
采集PMU Trace数据#
开启PMU Trace后,还需在运行时通过msprof开启指令级采集:
msprof --instr-profiling=on [--output=<数据存放路径>] python xxx.py
其中:
--instr-profiling=on:开启指令级Profiling采集--output:手动指定落盘路径,默认落盘在当前工作目录下
采集结果#
采集完成后,数据文件落盘在PROF_*/mindstudio_profiler_output/msprof_*.json中。开发者可在PyPTO Toolkit中加载该文件,进行核内流水分析。在PyPTO Toolkit的核内流水视图中,每对mark_stamp会显示为流水线上的尖峰标记,NOP填充使其在时间轴上形成可辨识的间隔。开发者通过匹配相同的 PMU ID,即可将时间轴上的流水片段定位到对应的leaf function,从而分析该计算阶段内各流水线(MTE2、MTE3、Vector、Cube等)的时序排布与利用率。
开箱性能调优#
算子初始性能与loop的写法、TileShape的设置最为密切。本章将介绍如何使用相关接口,在算子初始编写过程中直接得到较好的开箱性能。请参考PyPTO仓库的models文件夹内已开发算子的实现,进行新算子的开发。
正确选择loop写法#
由于不同root function之间的子图不能合并,而子图合并是PyPTO优化性能的关键手段,因此loop优化的核心原则是:增加root function的大小,减少它们的个数。
静态轴使用Python for循环#
pypto.loop方法会按当前轴循环展开成不同的root function。因此静态轴上的循环应使用Python的for循环,避免使用PyPTO的loop。
# ✅ 推荐:静态轴使用Python for
for i in range(batch_size):
result[i] = process(data[i])
# ❌ 避免:静态轴使用PyPTO loop
for i in pypto.loop(batch_size, name="LOOP_1", idx_name="i"):
result[i] = process(data[i])
调优效果可参考GDR算子案例3.3.1章节。
动态轴使用PyPTO loop并合理配置view#
当算子内有动态Shape时,动态轴的dim数值范围往往较广,需要使用loop循环处理。此时需要注意view视图的参数配置,选取的Shape范围不能过小,否则会限制后续TileShape的配置范围,导致每次循环的计算量过小,循环次数增加,部分运算还可能导致额外的重复搬运。比如矩阵乘运算,TileShape过小会导致大量的root function搬运相同的左矩阵或右矩阵。view TileShape为128的写法示例如下:
# 推荐:动态轴使用loop + unroll
bsz, h = x.shape
b = 128
b_loop = (bsz + b - 1) // b
for b_idx in pypto.loop(b_loop, name="LOOP_1", idx_name="b_idx"):
b_valid = (bsz - b_idx * b).min(b)
x_view = pypto.view(x, [b, h], [b_idx * b, 0], valid_shape=[b_valid, h])
# Matmul
pypto.set_cube_tile_shapes([128, 128], [128, 128], [128, 128])
y = pypto.matmul(x_view, W)
尽可能合并loop#
检查算子代码是否有可以合并的loop块,应当将其合并以增大root function。例如下面的两个loop就可以合并,进而提升Operation1和Operation2运算合并的可能,以减少y的冗余搬运。
bsz = x1.shape[0]
for b_idx in pypto.loop(bsz, name="LOOP_1", idx_name="b_idx"):
out_1 = Operation1(x1[b_idx, :], y)
for b_idx in pypto.loop(bsz, name="LOOP_2", idx_name="b_idx"):
out_2 = Operation2(x2[b_idx, :], y)
动态轴范围较广时使用 loop_unroll#
当算子使用动态Shape,且Shape范围较广的场景,应考虑使用loop_unroll代替loop接口。loop_unroll功能与loop类似,在其基础上增加了unroll_list参数支持多个展开方式。比如当算子中某个动态轴需要泛化支持1~64k的Shape范围时,指定单一的动态轴切分大小难以满足要求。切分过大时,小Shape场景会引入较多实际计算大小为0的空计算任务,增加耗时;切分过小时,大Shape场景下循环次数过多,影响整体性能。使用loop_unroll后,无论大小Shape场景,框架都会根据unroll_list参数选择合适的档位或组合,避免冗余计算,且循环次数可控,因此可获得较好的性能。
具体使用时注意以下几点:
伴随unroll_list参数配置的挡位数量增加,编译过程需要处理的任务量也成倍增加,导致编译时间变长。因此在最初编写算子时,建议使用较短的unroll_list,如[64, 16, 4]。
使用动态分档时应当注意不同档位可能需要分别选择合适的TileShape。
多层循环嵌套场景下,只有最内层的loop_unroll可以成功使用unroll_list参数。
参考示例如下:
'''
input:A, shape:[-1, 64]
output:B, shape:[-1, 64]
-1:表示动态Shape
'''
.....
for b, k in pypto.loop_unroll(A.shape[0] // 64, unroll_list=[64, 16, 4], name="A", idx_name='b'):
### 支持在不同的展开档位设置不同调优参数
if k <= 16:
pypto.set_vec_tile_shapes(16, 64)
else :
pypto.set_vec_tile_shapes(64, 64)
tile_a = A[b * 64:(b + k) * 64, :] #
tile_a = tile_a + 2
B[b * 64:, :] = tile_a
调优效果可参考GDR算子案例3.3.3章节。
合理设置TileShape初值#
TileShape配置的基本原理与使用约束等参考Tiling配置章节。其切分大小一方面直接决定了算子切分后的任务数量,从而决定了实际执行时的分核数、计算轮次。另一方面,切分大小从理论层面决定了算子的算数强度。因此,优化性能的关键是优化Tiling配置。
通常切分越大,算数强度越大,计算越容易达到Compute Bound,进而充分使能NPU的算力。这是由于,切分必然会引入重复搬运,切分越多重复搬运量越大,从而算数强度越低。而另一方面,切分大小又受片上多级缓存空间(L1、L0或UB)的限制而不能无限增加。
Matmul初始Tiling配置#
针对矩阵运算场景,以A、B矩阵均为DT_BF16或DT_FP16类型为例,满足Buffer空间约束的推荐Tiling配置为:
# Cube的相关计算建议采用如下的TileShape,可根据M、K、N实际尺寸选择最接近的配置:
pypto.set_cube_tile_shapes([128, 128], [64, 256], [256, 256])
pypto.set_cube_tile_shapes([256, 256], [64, 256], [128, 128])
pypto.set_cube_tile_shapes([128, 128], [128, 512], [128, 128])
以上Tiling配置的优点:
在满足L0 Buffer约束的条件下可以达到较大的算数强度;由于Tile大小需要满足分型格式的对齐要求,同时要考虑切分大小对于写入、写出带宽的影响,一般取128-256的组合。
后续进一步使用合图相关接口进行深度调优时,有机会开启Double Buffer,使能流水并行。
Vector初始Tiling配置#
针对向量运算场景,应该按照Operation和芯片UB大小来确定合适的TileShape。
首先,需要满足特定Operation对TileShape的规格约束。如scatter update要求尾轴TileShape和Shape一致,即不对尾轴进行切分。各个Operation的具体限制可以参考相关接口文档。
其次,要保证Operation的输入与输出Tensor可以在UB中分配内存,因此TileShape不能过大。同时由于子图和搬运的数据块较小会导致性能劣化,因此TileShape又不能过小。以Atlas A3 训练系列产品为例,UB的缓存容量为192kb。因此合适的初始TileShape是既满足Operation的要求,又使得数据块大小在16到64KB之间,尾轴32B对齐。
此外,归约类计算(Reduce运算,如:sum、max、min等)尽可能不要在归约轴上进行切分。例如,输入Shape为(56, 1024)的RMSNorm,它的最后一维TileShape应当设为1024。下图的上半部分是对reduce轴切分的RMSNorm的泳道图例子,多个子图的输出需要在同一个子图进行reduce操作,导致产生GM搬运和调度开销。下半部分是不对reduce轴切分的例子,此时上下游子图合并,没有GM搬运和调度开销。
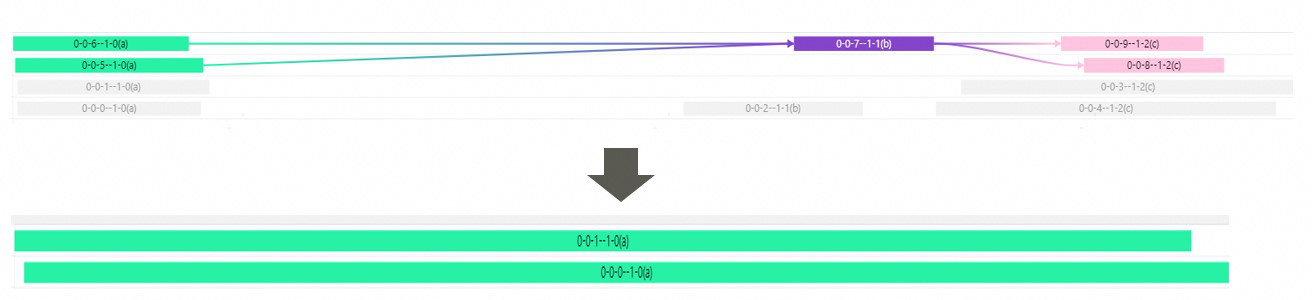
综上考虑,在初始算子开发阶段可以先使用如下设置,后续再结合泳道图数据进一步调优。
# Vector的相关计算建议采用如下的TileShape:
pypto.set_vec_tile_shapes(64, 512)
针对TileShape调优的实际效果可参考GDR算子案例3.2章节。
需要特别说明的是,上述Tiling配置并非一成不变,需要用户根据计算场景(考虑输入Shape、Dtype、Format等)以及硬件平台进行综合考虑。
其他注意事项#
检查输入矩阵、尤其是Shape较大的权重矩阵是否可以提前以NZ格式存储。NZ格式的数据搬运到L1的带宽更高。
矩阵乘前后有transpose时,可以尝试更换左右矩阵并使用左右矩阵转置的配置。由于N轴在尾轴上,因此当M轴较大、N轴较小时,也可以尝试该方法,使得左右矩阵有更大的尾轴,提升搬运带宽。
检查是否有不合理数据操作导致的冗余搬运,例如更换concat为assemble、尝试对reshape配置
inplace = True参数。
深度性能调优#
进一步调优算子性能需要采用man-in-loop的方式,通过获取并分析当前算子性能数据,针对性调整各性能配置参数,经过迭代调优逐步逼近最佳性能。算子性能数据可以通过泳道图获取,泳道图的采集和分析是算子调优过程中的重要一环,本章节的调优过程需要结合泳道图进行。
Stitch调优#
Stitch配置决定了多少个root function被同时下发调度,即该参数控制一次stitch能处理的最大loop数量,会同时影响调度开销、控制流生成耗时以及workspace内存占用。因此Stitch设置较大后任务可以充分并行,通常性能更优。当泳道图中出现大量空隙时,可能是Stitch配置的值太小导致的。
当前Stitch配置主要由stitch_function_max_num参数决定,在jit装饰器中完成配置,可参考如下配置:
@pypto.frontend.jit(
runtime_options={"stitch_function_max_num": 128}
)
以glm_attention.py算子为例,对比下该值的影响:
当该值过小(如配置为1)时,每个任务都需要同步,调度开销大,性能差。算子kernel耗时为1230us,端到端耗时(调度耗时+执行耗时)为1590us,对应泳道图如下:
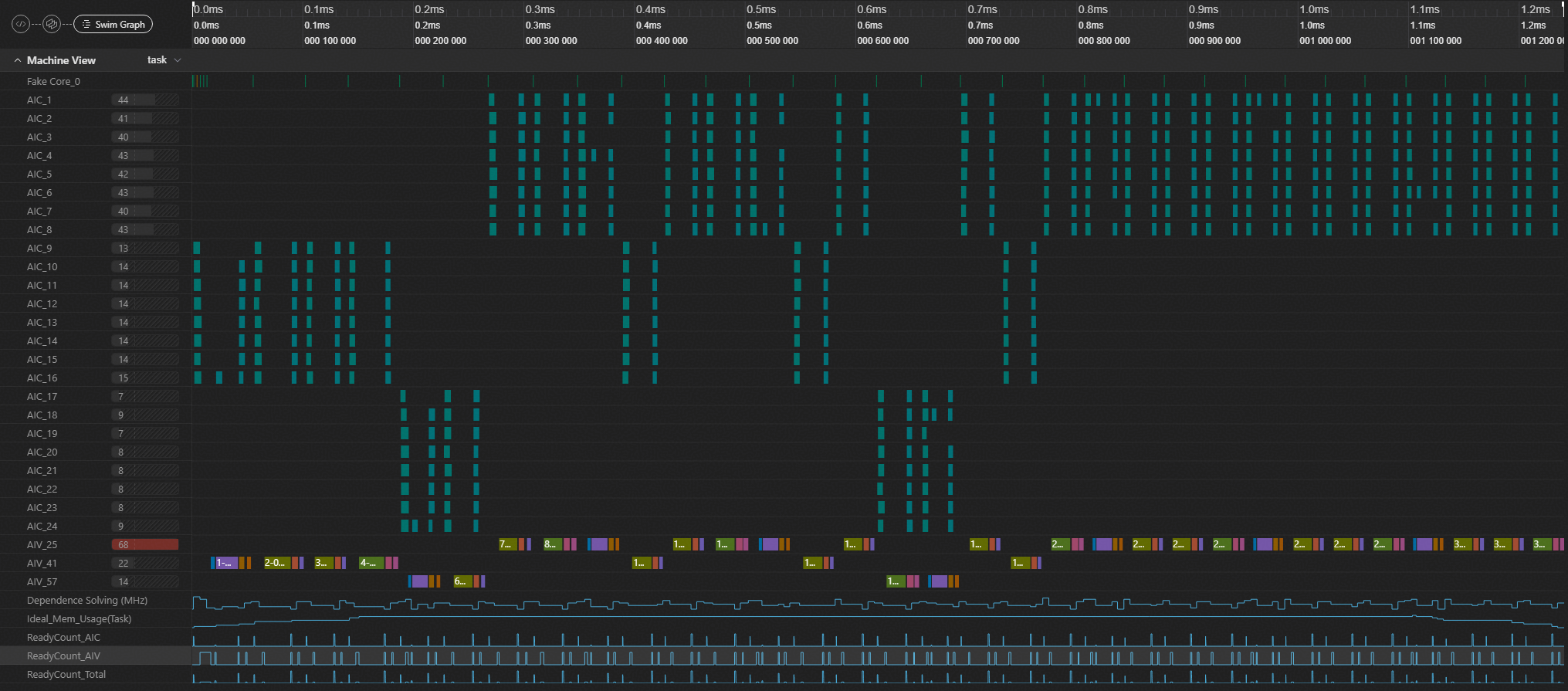
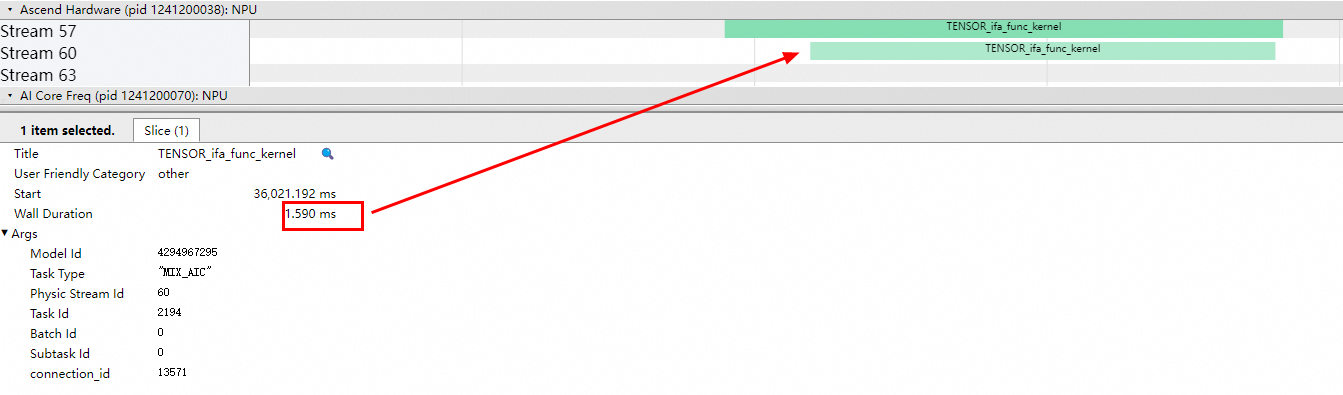
当该值增大为128时,泳道图明显更紧凑,调度与同步开销大幅降低。算子kernel耗时为180us,端到端耗时为803us,对应泳道图如下:
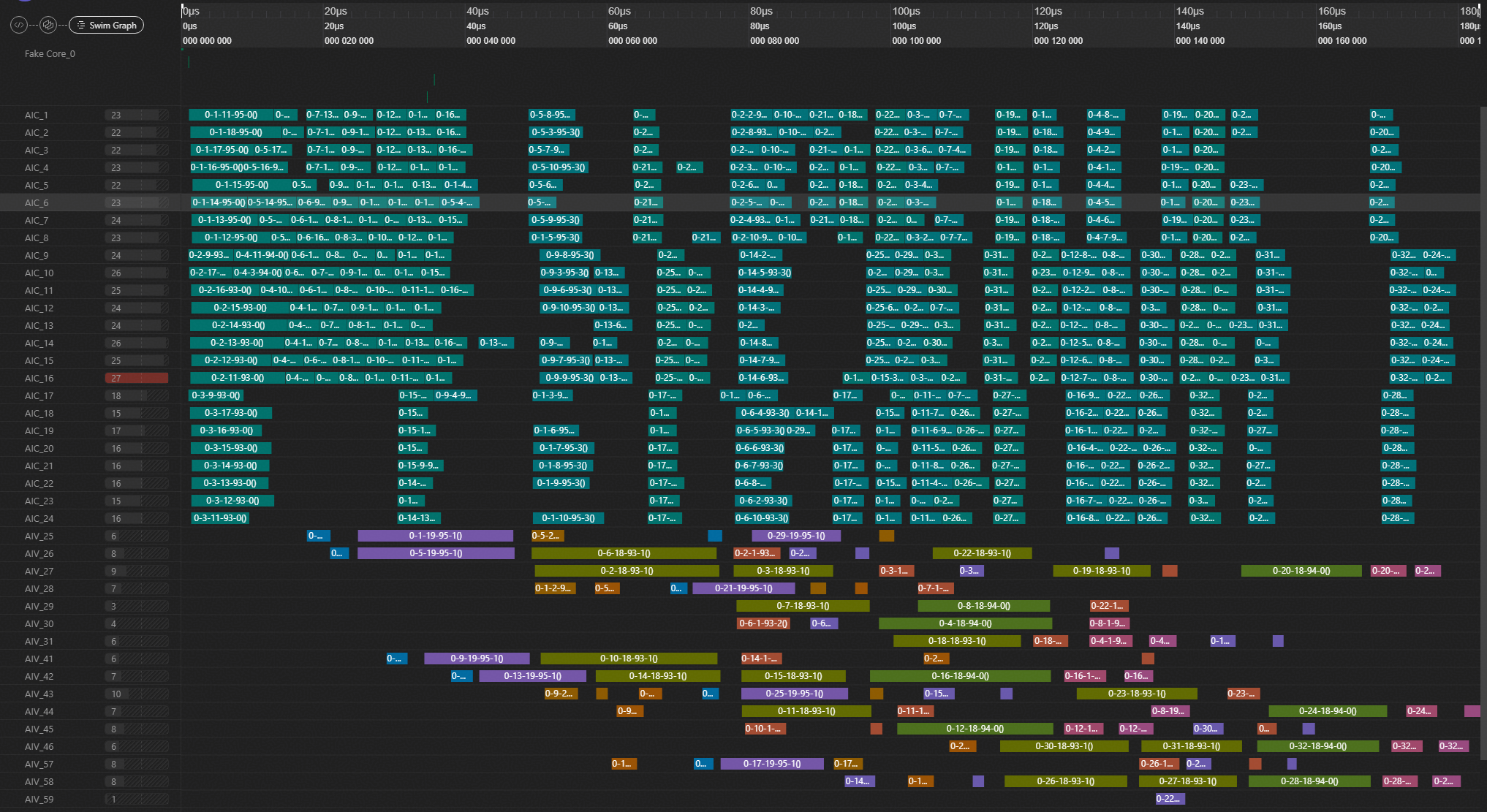
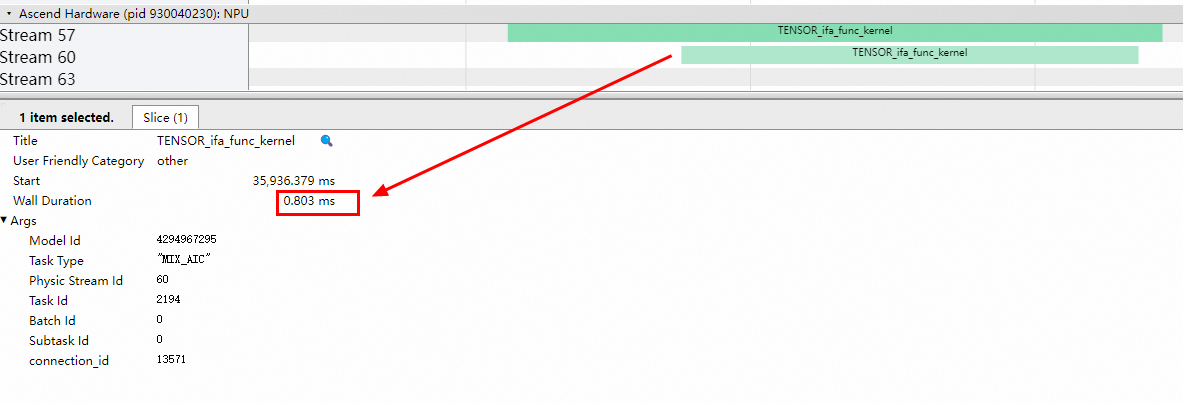
当该值继续增大为512时,泳道图更加紧凑,但调度耗时明显增加。算子kernel耗时为150us,端到端耗时为977us,对应泳道图如下:

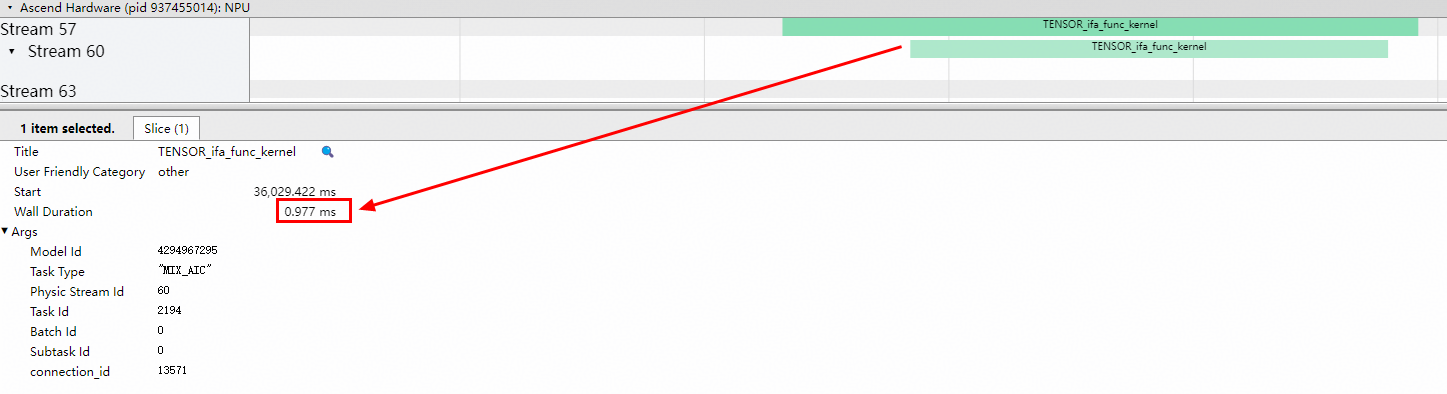
可见,随着Stitch配置的增大,算子kernel耗时持续减少。但是Stitch配置也并不是越大越好:
参数过大会导致调度耗时明显增加,进而导致端到端耗时得不偿失。
Stitch设置较大时workspace也会增加,大量任务并行,可能导致L2命中率较低。
调优建议:在内存资源允许的前提下,可逐步增大Stitch配置,结合泳道图和端到端总耗时数据调整stitch_function_max_num参数,寻找在性能收益与控制流开销之间的最佳平衡点,使总耗时减少。
实际效果还可以进一步参考GDR算子案例3.1章节。
TileShape调优#
Matmul TileShape调优#
进一步调优Matmul的TileShape,需要充分考虑对算数强度和带宽的影响,具体介绍见Matmul高性能编程章节。
当前环节主要关注减少重复载入和K轴分核两个调优手段,可对应set_cube_tile_shapes接口的enable_split_k配置参数。用户可以结合上述原理介绍,推导并选择合适的开关配置策略,也可以直接结合泳道图数据进行测试验证,择优配置。两个参数是相互解耦的,具体写法可参考如下配置:
pypto.set_cube_tile_shapes([128, 128], [64, 256], [256, 256], enable_split_k=True)
Vector TileShape调优#
Vector的TileShape配置除了需遵从前述章节介绍的原则以外,还需结合泳道图关注以下几点:
下游Vector Operation的TileShape尽可能使用上游Operation的输出TileShape。例如Transpose后接着一个Add Operation时,假设前者的TileShape设置为(64, 128),则后者的TileShape应该优先选择为(128, 64)。上下游Operation的TileShape对齐时,它们有着简单的一对一依赖,pass通常会自动将其合并在一个子图,达成融合算子的优化效果。如果没有合并,可以使用前文介绍的sg_set_scope或切图旋钮将其合并起来。上下游Operation的TileShape不对齐时,可能产生多对多依赖,无法正常合图。如下图所示,每一种颜色代表一种子图。当前后的Sqrt和Cast Operation使用相同的TileShape时,可以切出两个并行的融合子图;反之Sqrt和Cast Operation使用不同TileShape时,上下游子图之间是三对二的依赖,此时不能得到并行的融合子图。
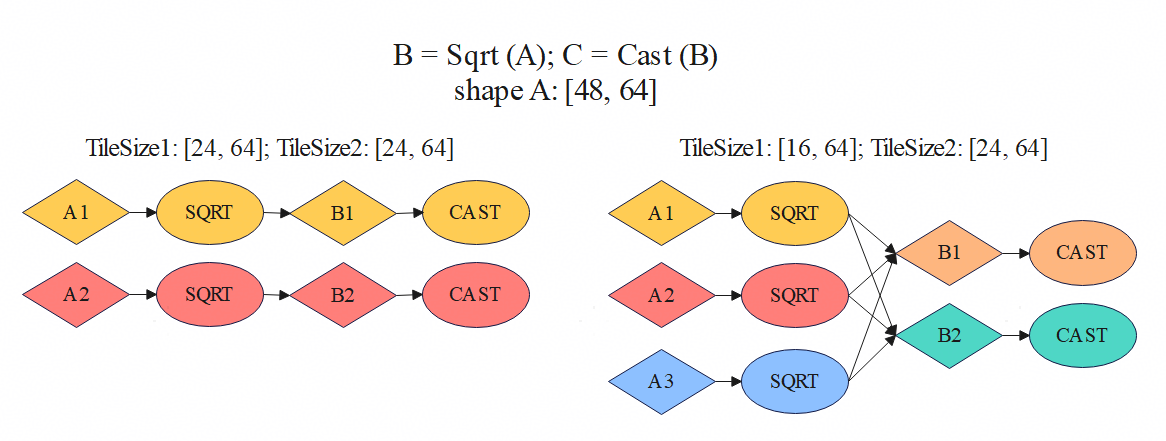
根据泳道图上的子图大小和并行度来调整TileShape。在优化目标的场景下,当泳道图上某一部分并行的核数较少(如只使用了不到一半的Vector核)时,应尝试减小该处Operation的TileShape。反之,泳道图上某一部分子图耗时较短、调度开销的耗时占比较高时,应尝试增大该处Operation的TileShape。需要注意的是这些调整应当避免在尾轴和规约轴上进行,因为这些轴上的TileShape应当符合前文所述的优化原则。另外,进行TileShape优化时可能会因为合图等原因导致OoO报错,此时应找到报错相关的Operation,将其TileShape调小,再进行上述的第三点优化。
调整相邻的Cube和Vector Operation的TileShape,使Cube子图和Vector子图之间依赖变得更简单,尽量避免多对多的依赖关系。
合图调优#
在优化合图相关旋钮之前,需要先完成TileShape的调优,因为不合适的TileShape会导致复杂的依赖关系,从理论上无法得到既多核并行又融合多个Operation的子图任务。
合图是指将计算图中多个逻辑上独立的Operation合并为一个逻辑子图,并由该子图最终生成一个物理计算内核(Kernel)的过程。深度学习模型的计算图往往由大量粒度较小的Operation构成,传统逐Operation执行模式下,每个Operation都会独立触发一次内核启动,计算完毕后将中间结果写回全局内存(GM)。这种执行方式在实际硬件上会引入显著的内核启动开销和冗余内存访问,难以充分发挥计算单元的全部计算能力。合图优化通过Operation逻辑聚合,使多个Operation在同一Kernel中协同执行。计算的中间结果得以保存在片上高速缓冲中,供下游Operation直接读取,同构消除冗余的GM读写,显著提升计算–访存比并改善整体执行效率。
在PyPTO编程模型中,开发者通过Tensor和Tensor Operation构建计算图。合图过程由编译器内部的优化Pass自动完成,用户无需手工编写融合Operation代码。合图Pass会在保证计算结果正确性的前提下,对计算图进行分析与重写,将原始计算图划分并重组为更适合目标硬件执行的子图。PyPTO的合图优化主要分为深度方向合图和广度方向合图两类,分别针对不同的性能瓶颈场景。
深度方向合图#
深度方向合图基于计算图中的生产者–消费者关系,沿数据依赖路径将前后相邻的Operation进行融合。该方式通过消除中间结果的写回操作,直接优化数据流路径,使原本受限于带宽的算子链得以在单个内核内一气呵成地完成计算。
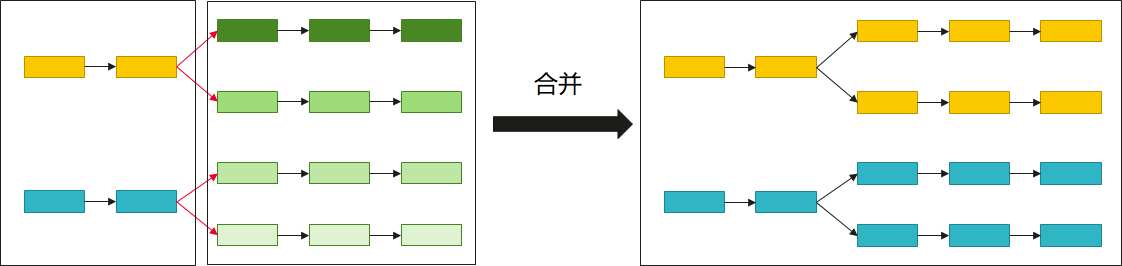
PyPTO框架在深度方向上已经实现了自动合图的功能,在极致性能优化场景下,可以手动指定合图方案,把operation操作分配到特定的计算任务中,进而改变各个任务的耗时,以实现负载均衡。通过配置set_pass_options接口的sg_set_scope参数实现该功能。
融合的目标通常来自于Operation间的依赖关系,例如上下游的两个Operation间传输的数据量较大时,应当将其合并以减少搬运耗时;或者多个Operation进行tile切分后变成多个并行的连通分支时,应当将这些Operation进行合并。融合的目标也可以来自于特定类型算子的固有经验,例如IFA算子切batch轴、s2轴和g轴后,V1和V2一般应各作为一个子图任务。
当前主要考虑在连续的Vector计算过程中使用该能力,暂不支持将Matmul Operation与Vector Operation进行合图。使用时需要结合泳道图信息进行分析和调整。具体使用方式可以参考案例:glm_attention.py。
广度方向合图#
广度方向合图针对计算图中处于同一层级、可并行执行的Operation,通过将多个并行Operation合并到同一Kernel中执行以增强单次Kernel的计算规模。在核内指令编排阶段,多分支融合能更充分地填充硬件流水,实现更优的多pipe并发。在访存层面,通过归并同源访存,将多次重复的GM到L1搬运整合为单次加载,在节省内存带宽的同时,有效摊薄了Kernel启动开销,最终提升了硬件计算单元的整体吞吐率。
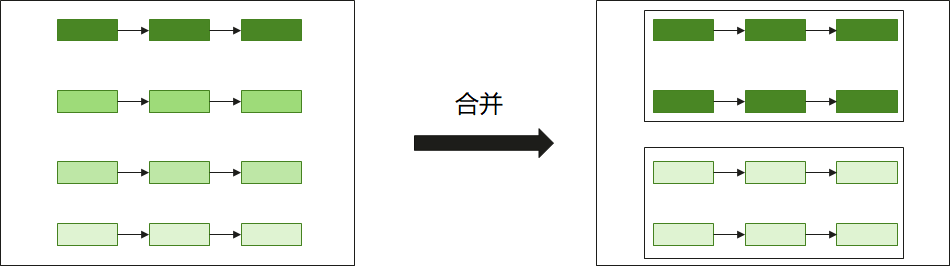
针对Matmul与Vector计算,PyPTO提供了不同的广度方向合图调优接口,将在接下来的章节分别详细介绍。
Matmul广度方向合图
Matmul运算场景下通过set_pass_options接口配置子图合并,主要可以选择L1Reuse和CubeNBuffer两种策略。两者都是用于在广度方向上合并Cube子图,前者用于合并具有冗余L1搬运的子图、后者用于合并同构的子图。L1Reuse可以减少L1搬运量,CubeNBuffer可以在不同分支的矩阵乘间隐藏搬运和计算耗时。它们都能减少子图调度开销,但考虑到大多数的矩阵乘场景的性能瓶颈都是数据搬运,因此优先使用L1Reuse策略减少数据搬运量。
实际上L1Reuse策略是默认开启的,且自动计算并配置子图合并数量。极致性能优化场景下可以通过cube_l1_reuse_setting参数进行手动配置,通常考虑2、4、8等值,可以结合泳道图实测数据择优配置。
cube_l1_reuse_setting支持函数粒度配置(func{magic}_{order}格式),可实现不同root function间的精细化控制:仅影响指定的function,不影响其他function。配置信息会直接展示在泳道图的hashOrder-hint字段中(格式l1ReuseInfo hashOrder: func8_0, subGraphCount: 24),可根据子图数量(subGraphCount)和核心数匹配合并力度。此外还支持基于semantic_label的配置,示例如下:
# 函数粒度配置
@pypto.frontend.jit(
pass_options={"cube_l1_reuse_setting": {"DEFAULT": 4, "func8_0": 1, "func8_1": 1}}
)
# semantic_label配置(可与函数粒度key共存)
@pypto.frontend.jit(
pass_options={"cube_l1_reuse_setting": {"C1": 4}}
)
CubeNBuffer针对的是不能使能L1Reuse的场景,此类场景较少,主要有以下两种:
Cube子图间没有重复L1搬运。如BatchMatmul的左右矩阵Shape分别为(128,64,64)和(128,64,64)时,pass切出128个左右矩阵Shape分别为(64,64)和(64,64)的同构Cube子图后,它们之间没有重复L1搬运。还有FA算子的MM2,不同S2 block的MM2子图之间没有重复L1搬运。
K轴很长。当没有进行切K时,L1Reuse要求左矩阵的一整行或右矩阵的一整列数据块驻留在L1中。而L1缓存容量有限。因此当K轴较长、且没有切K时,无法使用L1Reuse。
此时可以配置cube_nbuffer_setting参数,并结合泳道图实测数据进一步调优。可参考案例mla_prolog_quant_impl.py
Vector广度方向合图
Vector运算场景下通过set_pass_options接口的vec_nbuffer_setting参数配置广度方向的合图操作。需要注意的是,应先进行前面的优化步骤将上下游子图的切分和合并调到较合适后,再尝试使用vecNBuffer来进行广度合并。当泳道图内有同构子图组具有大量的小子图(耗时在10u以下)时,应该使用该功能进行优化,以减少调度开销和kernel的头开销。
vec_nbuffer_setting参数的配置方式与cube_nbuffer_setting相似,可参考案例sparse_flash_attention_quant_impl.py
调度策略调优#
PyPTO算子的核间的流水由AICPU对子图的调度确定,它基于子图间的依赖关系和核间任务的调度策略。可以尝试更改该调度策略以达到更优的算子性能。当上下游子图之间依赖较为简单,或下游子图输入Tensor的L2命中率较为重要时,推荐使用L2亲和调度,配置方式如下:
@pypto.frontend.jit(runtime_options={"device_sched_mode": 1})
具体配置时应综合考虑L2复用与负载均衡的影响,不同场景的最佳配置策略不同,应结合泳道图具体分析。
其他调优方法#
特殊Shape时可以尝试使用Vector操作提前处理输入矩阵,使其变成更标准的Shape。以左右矩阵Shape分别为(884736,16)和(16,16)的矩阵乘为例。如果只使用L1Reuse,只能优化到500us。而使用下面的写法,提前将四个重复的右矩阵在对角线拼成一个Shape为(64,64)的新的右矩阵c,将它和Reshape后的左矩阵做矩阵乘,则算子性能大幅提升到40us。
def matmul_kernel(a, b, out):
# 构造c
pypto.set_vec_tile_shapes(64, 64)
d = pypto.full([16, 16], 0.0, pypto.DT_BF16)
c1 = pypto.concat([b, d, d, d], 1)
c2 = pypto.concat([d, b, d, d], 1)
c3 = pypto.concat([d, d, b, d], 1)
c4 = pypto.concat([d, d, d, b], 1)
c = pypto.concat([c1, c2, c3, c4], 0)
# a变形
a = pypto.reshape(a, [221184, 64])
# 矩阵乘
pypto.set_pass_options(cube_l1_reuse_setting={"DEFAULT": 9})
pypto.set_cube_tile_shapes([512, 512], [64, 64], [64, 64], True)
e = pypto.matmul(a, c, pypto.DT_BF16)
e = pypto.reshape(e, [884736, 16])
pypto.assemble(e, [0, 0], out)
增加冗余计算来避免冗余依赖和搬运。这些下面是PyPTO仓库的glm_moe_fusion.py的示例,通过将e_score_bias_2d复制tile_batch份后进行cast操作,使得每一份的cast都和对应batch的其他操作进行了合图。这避免了e_score_bias_2d的cast操作和每个batch的后续计算产生一对多的子图依赖、增加调度开销,还避免了cast结果的搬运。
e_score_bias_2d_tile = pypto.tensor([tile_batch, ne], e_score_bias_2d.dtype, "e_score_bias_2d_tile")
for tmp_idx in range(tile_batch):
pypto.assemble(e_score_bias_2d, [tmp_idx, 0], e_score_bias_2d_tile)
e_score_bias_2d_cast = pypto.cast(e_score_bias_2d_tile, tile_logits_fp32.dtype)
尽量避免处理尾轴长度较小的Tensor。使用较大的TileShape也无法避免Operation的输入Tensor的尾轴较小时,可以使用concat、transpose或reshape等数据操作Operation来增大尾轴。
通过set_cache_policy设置合理的L2 CacheMode,对于只访问一次的Global Memory数据设置其访问状态为不进入L2 Cache。
当进行上述优化后算子性能仍然较差时,需要考虑TileOperation本身实现是否较差。可以构造单独Operation的用例与Ascend C小算子的性能对比,确认性能较差后检查是否没有使用更优的指令。