已知问题#
使用未初始化的Tensor#
问题现象描述#
使用pypto.tensor声明了一个Tensor,误以为它与torch.empty类似。会申请一块未初始化的内存。在再次写入前直接读取它(如使用 view),会导致框架校验错误或精度问题。
问题原因#
在PyPTO中,除了使用pypto.full、pypto.zeros等显式包含初始化行为的Tensor声明外,还可以使用pypto.tensor声明 Tensor,但该接口不包含初始化行为。在PyPTO中,每个Tensor必须先写后读,即必须先有producer,然后才能有consumer,未初始化的Tensor不申请内存。框架中通常会校验直接使用no producer Tensor并报错,但有时因校验遗漏,可能会导致上板精度错误。
处理步骤#
避免使用未经初始化的Tensor。
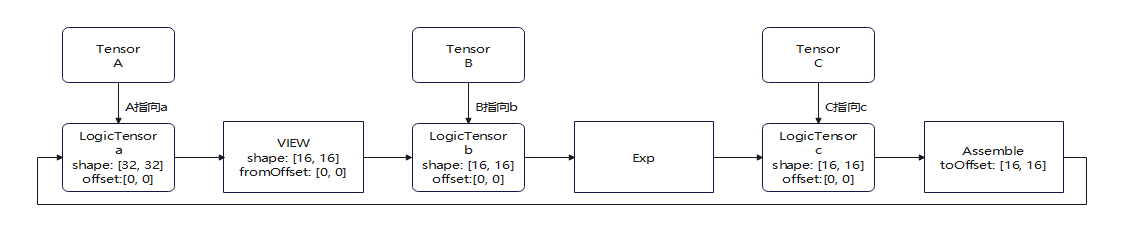
同一个Tensor进行View和Assemble导致图成环报错#
问题现象描述#
示例代码如下:
@pypto.frontend.jit
def foo_kernel(x, y):
pypto.set_vec_tile_shapes(16, 16)
a = pypto.zeros([32, 32])
b = a[:16, :16] # 从a中view获取数据
a[16:, 16:] = b.exp() # 计算后assemble写回a
y[:] = x + a
torch.npu.set_device(0)
x = torch.ones(32, 32, dtype=torch.float32)
y = torch.empty(32, 32, dtype=torch.float32)
foo_kernel(pypto.from_torch(x), pypto.from_torch(y))
执行时报错:ASSERTION FAILED
ERROR:root:Record function foo_kernel failed: ASSERTION FAILED: outDegree[opToIndex[op.get()]] == 0
详细报错如下:
ERROR:root:Record function foo_kernel failed: ASSERTION FAILED: outDegree[opToIndex[op.get()]] == 0
Operation not fully processed: /* /home/pypto-dev/a.py:9 */
<32 x 32 x DT_FP32 / 32 x 32 x DT_FP32> %0@2#(-1)MEM_UNKNOWN::MEM_UNKNOWN = !10000 VEC_DUP(g:-1, s:-1) #SCALAR{0.000000} #op_attr_shape{[32, 32]} #op_attr_validShape{[32,32]}
, func GetSortedOperations, file function.cpp, line 1105
libtile_fwk_interface.so(npu::tile_fwk::Function::GetSortedOperations() const+0xb3c) [0xffff9c2f6650]
libtile_fwk_interface.so(npu::tile_fwk::Function::SortOperations()+0x38) [0xffff9c2f6f28]
libtile_fwk_interface.so(npu::tile_fwk::Function::EndFunction(std::shared_ptr<npu::tile_fwk::TensorSlotScope> const&)+0x960) [0xffff9c31b8d0]
libtile_fwk_interface.so(npu::tile_fwk::Program::FinishCurrentFunction(std::shared_ptr<npu::tile_fwk::TensorSlotScope> const&, bool)+0x1b0) [0xffff9c532274]
libtile_fwk_interface.so(npu::tile_fwk::Program::EndFunction(std::string const&, bool)+0x10c) [0xffff9c536dcc]
libtile_fwk_interface.so(npu::tile_fwk::Program::EndHiddenLoop(npu::tile_fwk::Function*, bool)+0xb0) [0xffff9c537384]
libtile_fwk_interface.so(npu::tile_fwk::Program::EndFunction(std::string const&, bool)+0x5c) [0xffff9c536d1c]
libtile_fwk_interface.so(npu::tile_fwk::RecordLoopFunc::IterationEnd()+0x44) [0xffff9c5399c4]
libtile_fwk_interface.so(npu::tile_fwk::RecordLoopFunc::Iterator::operator!=(npu::tile_fwk::RecordLoopFunc::IteratorEnd const&)+0xfc) [0xffff9c539ea0]
原因分析#
该报错的原因是内部在对基本算子做拓扑排序时发现存在环路的报错。
这是由于数据从a中读取又写回a导致的。
由于pypto描述的是一个图表达,在读取和写入的时候,当前认为a是一个整体,因此创建的连接关系会形成一个环路,即a->b->b.exp()->a,而pypto不允许构造出的图内存在环路,必须为DAG(有向无环图),所以才有这个报错。
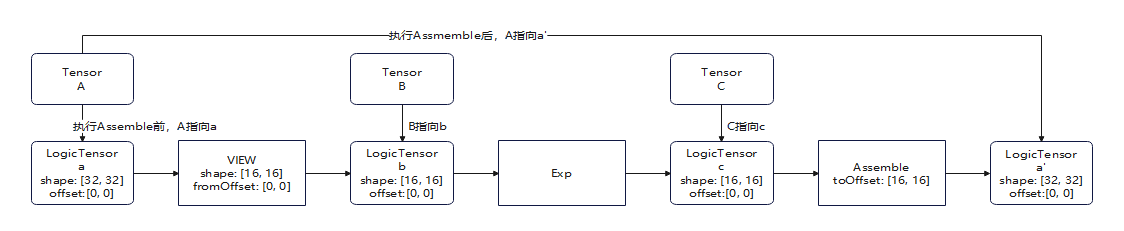
解决措施#
当前需要将读取和写入a的逻辑拆分成两个图去定义,避免一个图内存在环路。
后续等Assemble的SSA语义上线后使用该写法不会有问题。
同一个算子多次执行时,静态轴传入不同的运行时值(或者动态轴缺少标注)#
问题现象描述#
精度错误,或者AI CPU/AI Core异常。
可能原因#
由于编译时会针对静态轴进行固定大小的切分,因此切分的数量也是固定的。这意味着一次编译后的代码只能处理一个特定的静态轴。如果传入的静态轴与首次编译时的不一致,切分后访问的内存地址可能会超出实际传入的Tensor的大小,导致内存访问错误,或对其他Tensor造成干扰,从而引发精度异常。
处理步骤#
方案1:针对每一次不同的静态值,定义不同的算子。
def handler(in): # 定义公共处理函数 return pypto.add(in, in) @pypto.frontend.jit def adder_256(in_shape_256): # 定义处理in 轴大小是256的场景 return handler(in_shape_256) @pypto.frontend.jit def adder_1024(in_shape_1024): # 定义处理 in 轴大小是 1024 的算子 return handler(in_shape_1024) adder_256(in_256) adder_1024(in_1024)
方案2:定义为动态轴
@pypto.frontend.jit def adder(in_shape): # 定义处理in 轴大小是256的场景 out = Tensor(in_shape.shape[0]) for k in pypto.loop(in_shape.shape[0] / 256): out[k * 256: k *256 + 256] = pypto.add( in[k * 256 : k * 256 + 256], in[k * 256 : k * 256 + 256]) return handler(in_shape_256)
父循环内跨多个子循环的Tensor内存不支持在每次父循环迭代中分配#
问题现象描述#
两层或者两层以上循环嵌套下,在父循环中定义了一个 tensor,在一个子循环中写入该 tensor,在另一个子循环中使用该 tensor 时,存在精度错误。
可能原因#
在该GM上的Tensor,在父循环的多次迭代中,每次迭代分配的内存地址相同,导致不同迭代本应使用不同的临时内存来保存数据,但实际上使用了相同的地址。由于不同循环迭代实际上是并行执行的,因此当多个迭代同时进行时,后执行的迭代会覆盖前一次迭代的临时内存,从而导致精度问题。
处理步骤#
在后一个子循环中添加submit_before_loop = True,以在启动该子循环前下发任务,强制多次迭代串行运行,从而避免并行执行时因内存覆盖和冲突导致的精度问题。
for outer in pypto.loop(...): # 父循环,执行至少两次,如果只执行一次,不存在多次并行覆盖的问题
t = pypto.Tensor(...) # 定义一个临时tensor
for inner0 in pypto.loop(...): # 第一个子循环,对临时tensor t赋值
...
t[...] = ...
# 添加 submit_before_loop,确保父循环多次迭代不在同一个并行执行块中
for inner1 in pypto.loop(..., submit_before_loop=True): # 第二个子循环,使用了临时 tensor t,
x[:] = t[:] + t[:]
SymbolicScalar不支持循环内自增#
问题现象描述#
@pypto.frontend.jit
def add_kernel_1(a, b, c):
count = 0
for i in pypto.loop(20):
count = count + 1
当实际执行到i = 1时,count并不会像用户预期的那样从0依次增加到20。
可能原因#
当前PyPTO框架仅捕获了用户的Tensor操作,而未捕获用户的scalar操作,因此不会将count处理为变量。目前,只有循环变量能够实现自增。
处理步骤#
使用循环变量来表达自增逻辑。
已安装torch_npu,但未安装cann时,执行仿真异常#
问题现象描述#
在仿真环境中执行算子时,出现失败,报错信息如下。
ImportError: libhccl.so: cannot open shared object file: No such file or directory
问题原因#
当程序启动时,torch(版本>2.5)会自动加载所有名为“torch.backends”的扩展(例如 torch npu)。如果环境中已安装了torch_npu但未安装CANN,由于找不到依赖项,将会引发异常。
处理步骤#
在执行算子之前,添加以下环境变量,可以避免上述异常。
export TORCH_DEVICE_BACKEND_AUTOLOAD=0