精度调试#
简介#
当PyPTO算子执行后无功能告警或报错,但输出数据不符合预期时,可基于以下方法进行精度问题的定界和定位。精度问题主要来源于两个方面:
功能错误:硬件静默故障、软件静默功能问题、公式实现错误引起的明显数据错误或误差。
计算误差:数据类型、算法(切分、累积、公式近似)差异等引起的明显数据误差。
整体流程#
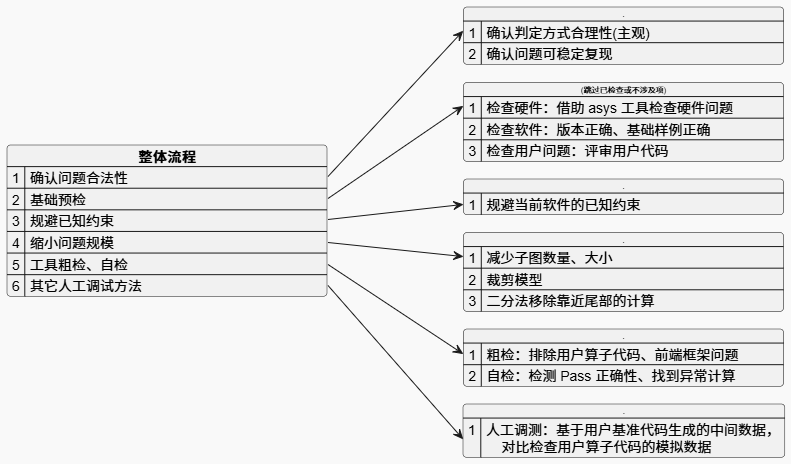
确认问题合法性#
步骤一:确认问题判定方式是否合理(经验判断与实验证明)。
误差阈值是否使用合理,例如:
存在bfloat16等低精度数据类型的算子使用了float32的误差阈值。
计算路径较深的算子使用了小算子的误差阈值。
对于不合理部分根据经验进行修正,若问题消失则完成精度调试。
步骤二:确认问题可稳定复现。
重复执行多轮输出数据一致且为异常值。
更换其它环境多轮输出仍旧一致且为异常值。
若无法稳定复现则明确为功能问题,建议中止精度调试。
基础预检#
基础预检为指导性说明,指出常见但易被忽视的高概率出错问题。如果用户或调试人员确认相应检查项无误,可以跳过这些步骤。
借助asys工具检查硬件问题。
使用硬件自检工具排除硬件安装问题。
使用硬件压测工具排除硬件故障。
检查软件问题。
基于安装指导确认软件版本正确。
执行项目中example用例,确认结果正确。
检查用户侧是否引入问题。
多方评审算子代码,确认:
计算过程与算法原型一致。
数据类型、计算类型与竞品实现一致(若无竞品实现,需由提供算子实现方案的设计人员完成类型确认)。
若无法确认,则分析后续发现的问题点时,需额外分析是否为用户侧引入。
规避已知问题#
精度调试前,应确保已规避当前软件存在的已知问题,详细请参见已知问题。
缩小问题规模#
缩小问题规模通常是一个可选步骤,旨在简化问题,提高复现和定位的效率。
缩小问题规模后需能复现同样问题,然后继续进行后续的工具自检或人工调试
对于缩小后出现新问题的情况,建议尝试其它缩小方法以复现原始问题,不建议将新问题纳入关键定位流程。
然而,在某些情况下,缩小问题规模是必选步骤,例如对于较大的模型:
主机内存不足导致自检工具无法执行。
文件存储空间过小导致自检工具无法保存中间计算数据。
其它分析流程或工具的耗时超过主观容忍范围,甚至无法执行等阻塞式情况。
通常通过以下方法缩小问题规模:
减少子图数量和大小。例如减少loop的次数或减少cube/vector Tiling块的个数(即增大TileShape的大小)。
裁剪模型。例如调小模型的Shape规格,如batch_size、seq_len等。
采用二分法移除尾部计算。
按模型计算的顺序,采用二分法移除靠近尾部的计算,并将断开的输出加入算子的输出列表。
执行算子并观察、分析新的输出列表
如果数据正常(无inf/nan、无主观认为随机的值、或与参考基准数据误差较小)则返回上步继续二分操作。
如果数据存在异常,则将代码恢复到本次移除前的状态,作为最新的候选问题场景。
如果裁剪后的模型规模已经很小,可以停止二分操作并选择最新的候选问题场景进行后续的定位。
工具自检和分析#
工具简介#
PyPTO在计算图编译的各Pass阶段拥有完整的中间表示,可翻译成第三方计算代码,并在其它计算单元(例如Host CPU)上模拟计算过程。该工具通过模拟计算结果与基准数据的误差对比,可以检测算子异常或者某个Pass的处理结果是否存在异常,并定位首个出现异常的计算节点。
主要特性及使用场景:
Tensor Graph校验:用于校验算子代码、框架前端处理的正确性。基于用户提供的基准(golden)输入输出数据,与Tensor Graph模拟计算的最终结果对比检测整体计算的正确性。常用于以下情况:
当用户存在可用的算子基准(golden)输入、输出数据时,可先使能粗检特性粗略排除算子代码、框架前端处理是否引入差异。
Pass阶段校验:用于自检Pass的正确性。基于各Pass模拟计算的结果,对比检测Pass正确性及异常计算节点。常用于以下情况:
当用户算子精度刚刚出现问题且没有明确方向,可先使能自检特性排除Pass处理阶段是否引入潜在错误。
当用户大致明确某个Pass出问题时,使能自检特性获取该Pass及前序Pass的模拟计算中间数据,对比数据找出潜在出问题的计算操作。
中间结果分析:指定单个计算结果,保存到文件或者以可读形式打印到输出、日志。
当Tensor Graph校验失败时,可使用pass_verify_print/pass_verify_save特性打印、保存模拟计算的中间数据,对比数据找出潜在出问题的计算操作。
使用约束#
当前精度调试工具存在以下限制(完整计算流表示仅保存在pass运行上下文中),无法使用检测功能:
不支持上板执行的中间数据检查,仅支持前端及pass的检查。
不支持特定pass,特定pass(例如SubgraphToFunction)属于中间的优化过程缺少完整计算信息,工具内部做自动跳过处理。
不支持pass间的自动对比校验(需人工进行数据对比)。
不支持程序退出后在任意运行环境构造并模拟计算。需在算子编译期间,所对应的主机CPU及进程上构造并模拟计算。
不支持基于昇腾AI处理器调用Ascend C构造并模拟计算。
不支持基于GPU构造并模拟计算。
不支持包含GATHER_IN_UB和GATHER_IN_L1两个operation的校验。
如ExpandFunction校验结果出现B200BU报错,则该场景仅在InferDynShape后校验结果有效。
inplace的op目前只确保pass24及以后的pass校验通过。
环境准备#
确认编译工具符合以下要求:
cmake >= 3.16.3
make
g++ >= 9.4.0
工具使用操作步骤#
开启精度调试开关。参考样例为:hello_world.py。
... verify_options = { "enable_pass_verify": True, "pass_verify_save_tensor": True, ... } @pypto.frontend.jit(verify_options=verify_options) def add_kernel( input0: pypto.Tensor((1, 4, 1, 64), pypto.DT_FP32), input1: pypto.Tensor((1, 4, 1, 64), pypto.DT_FP32), out: pypto.Tensor((1, 4, 1, 64), pypto.DT_FP32), ): pypto.set_vec_tile_shapes(1, 4, 1, 64) out[:] = input0 + input1 ...
verify_options参数说明
参数名
类型
默认值
说明
enable_pass_verifybool
False
总体使能开关,决定所有
pass_verify_*选项和接口是否生效。必须设置为True才能使其他参数生效pass_verify_save_tensorbool
False
是否将模拟计算数据存盘。设置为
True时会在{work_path}/output/output_*/目录下生成verify_*目录pass_verify_save_tensor_dirstr
“{RUNNING_DIR}/output/output_{TS}”
检测结果及数据的保存路径。可指定绝对路径
pass_verify_pass_filterList[str]
空
配置待自检的Pass名称列表。不指定则默认校验特定pass;指定
"all"则校验所有pass;指定[]不校验pass只校验tensor_graphpass_verify_error_tolList[float]
[1e-3, 1e-3]
精度对比的容差配置。第一个值为相对误差容差(rtol),第二个值为绝对误差容差(atol)
设置golden数据(可选)
如果需要进行tensor_graph验证,需要设置golden数据:
... def test_add(): shape = (1, 16, 1, 64) input_data0 = torch.rand(shape, dtype=torch.float) input_data1 = torch.rand(shape, dtype=torch.float) torch_add = torch.add(input_data0, input_data1) # 设置golden数据 pypto.set_verify_golden_data(goldens=[None, None, torch_add]) input_data0 = input_data0.to('npu') input_data1 = input_data1.to('npu') out = torch.empty(shape, dtype=torch.float, device='npu') add(input_data0, input_data1, out) ...
set_verify_golden_data接口说明
函数原型:
set_verify_golden_data(in_out_tensors=None, goldens=None)
参数说明:
参数名
类型
说明
in_out_tensorsList[Union(pypto.Tensor, torch.Tensor)]
将用户(可选)执行算子时实际的输入、输出列表按照相同位置对应地设置到检测工具。jit调用模式下,该选项不需设置
goldensList[Union(pypto.Tensor, torch.Tensor)]
将用户已有的计算基准数据(golden)输出设置到工具中做对比检测。该列表与算子输入、输出参数列表的长度一致、位置对应。若相应位置设置为None,表示跳过该位置的数据对比。注意:torch.Tensor的device属性需为CPU,不支持NPU
约束说明:
该函数需设置
pypto.set_verify_options(enable_pass_verify=True)后生效
执行修改后用例。
python3 examples/00_hello_world/hello_world.py查看校验结果。
默认情况下,校验结果不会打印到终端,而是写入
{work_path}/output/output_*/verify_*/interpreter.log。执行结束后可用以下命令查看:# 查看最新 verify 目录中的 interpreter.log cat $(ls -td output/output_*/verify_* 2>/dev/null | head -n 1)/interpreter.log
日志中
[EVENT]行表示通过(PASS)或跳过(NO_COMPARE),[ERROR]行表示未通过(FAILED)。典型内容如下:[2025-mm-dd HH:MM:SS][EVENT][tid:12345] tensor_graph Verify for 3 data view list index 0 result NO_COMPARE [2025-mm-dd HH:MM:SS][EVENT][tid:12345] tensor_graph Verify for 3 data view list index 1 result NO_COMPARE [2025-mm-dd HH:MM:SS][EVENT][tid:12345] tensor_graph Verify for 3 data view list index 2 result PASS [2025-mm-dd HH:MM:SS][EVENT][tid:12345] function_TENSOR_loop_0_Unroll1_PATH0_hiddenfunc0_8_Pass_00_ExpandFunction Verify for 1 data view list index 0 result PASS ... [2025-mm-dd HH:MM:SS][EVENT][tid:12345] function_TENSOR_loop_0_Unroll1_PATH0_hiddenfunc0_8_Pass_36_CodegenPreproc Verify for 1 data view list index 0 result PASS [2025-mm-dd HH:MM:SS][ERROR][tid:12345] [VERIFY]:ErrCode: 0xB4001U! function_TENSOR_loop_0_Unroll1_PATH0_hiddenfunc0_8_Pass_09_SplitLargeFanoutTensor Verify for 1 data view list index 0 result FAILED
如需同时将日志镜像到终端,可设置环境变量
ASCEND_SLOG_PRINT_TO_STDOUT=1后重新执行用例。执行结束后,在${work_path}/output/output_*/目录(*代表时间戳)下生成verify_*目录,存放检测结果文件与日志。
├── tensor_graph # 保存前端初始计算图模拟计算后的中间数据,作为基础数据 │ ├── *.data │ └── ... ├── verify_graph_data_metainfo.csv # 结果报告,保存中间数据元信息及对应数据文件名 ├── verify_graph_result_brief.csv # 精度比对摘要(PASS/FAIL/NO_COMPARE、误差统计等) ├── verify_graph_result_brief.log # 精度比对异常详情(失败项、异常路径、错误明细) ├── interpreter.log # 校验结果与 interpreter 执行日志(默认记录 ERROR / EVENT,含 PASS / FAIL / NO_COMPARE) ├── Pass_{PASS_SEQ}_{PASS_NAME} # 保存中间pass计算图模拟计算后的中间数据,作为待测数据 │ ├── *.data │ └── ...其中,
verify_graph_result_brief.log和interpreter.log位于同一个verify_*目录下:verify_graph_result_brief.log:偏向校验结果摘要与异常明细(对比失败、异常路径)。interpreter.log:校验 PASS / FAIL / NO_COMPARE 结果及 interpreter 执行过程日志(见步骤 4);默认仅 ERROR / EVENT 级别落盘,不输出到终端。
后续处理建议。
对于tensor_graph校验结果中标记FAIL的情况,建议:
多方评审检查PyPTO前端代码的正确性。
在前端代码无明显异常的前提下,可使用
pass_verify_print和pass_verify_save保存/打印中间结果进行进一步分析(详见步骤7)。
对于tensor_graph校验结果通过,Pass阶段校验结果中标记FAIL的情况,建议:
建议收集相关结果信息,并提交ISSUE进行处理。
使用
pass_verify_print和pass_verify_save分析中间结果(可选)。使用场景:当Tensor Graph校验失败时,可使用这两个接口打印、保存模拟计算的中间数据,对比数据找出潜在出问题的计算操作。
重要说明:
pass_verify_print和pass_verify_save保存的是tensor graph验证阶段模拟计算的结果这些结果是在主机CPU上通过模拟执行计算图得到的
与实际在NPU上板执行的结果可能存在差异,主要用于算法逻辑验证
使用示例:
@pypto.frontend.jit(verify_options=verify_options) def add_kernel( input0: pypto.Tensor((1, 4, 1, 64), pypto.DT_FP32), input1: pypto.Tensor((1, 4, 1, 64), pypto.DT_FP32), out: pypto.Tensor((1, 4, 1, 64), pypto.DT_FP32), ): pypto.set_vec_tile_shapes(1, 4, 1, 64) # 保存中间结果到文件 pypto.pass_verify_save(input1, "input1_by_pass_verify") # 打印中间结果到控制台 pypto.pass_verify_print(input0) out[:] = input0 + input1 def add(input_data0, input_data1, out): add_kernel(input_data0, input_data1, out) def test_add(): shape = (1, 4, 1, 64) input_data0 = torch.rand(shape, dtype=torch.float, device='npu') input_data1 = torch.rand(shape, dtype=torch.float, device='npu') out = torch.empty(shape, dtype=torch.float, device='npu') add(input_data0, input_data1, out) ...
执行修改后用例
python3 examples/00_hello_world/hello_world.py控制台输出示例:
input0:<64x64xFP16/64x64xFP16> [[0.03955 0.6094 0.1519 ... 0.7339 0.8789 0.8662] [0.6284 0.01465 0.6333 ... 0.2422 0.03516 0.8423] [0.231 0.02686 0.6055 ... 0.7466 0.2529 0.2231] ... [0.3477 0.4243 0.05273 ... 0.9287 0.1138 0.5083] [0.05273 0.9941 0.4985 ... 0.8345 0.8613 0.188] [0.3184 0.8047 0.833 ... 0.7734 0.2578 0.1392]]
生成的文件结构:
执行结束后,在
{work_path}/output/output_*/目录(*代表时间戳)下生成tensor/目录:├── tensor/ │ ├── input1_by_pass_verify.data # 保存的指定模拟计算数据,格式为Tensor数据的直接内存转储 │ ├── input1_by_pass_verify.csv # 模拟计算数据的元数据,包括数据类型、shape信息
后续数据处理建议:
根据元数据信息使用常用的
torch.from_file()、numpy.load()等接口打开数据文件并转换为可解析的数值,再进一步进行通常开发者使用的数据分析方法,例如:检查异常数据的偏移规律、异常数据的值特征(inf/nan/zero等)。
上板执行tensor dump#
功能概述#
支持在上板执行时dump leaf function的输入输出数据,用于精度问题定位,支持和模拟计算结果对比分析。
启用方式#
import os
# 设置环境变量启用上板dump,或者执行前单独设置环境变量export PYPTO_DATADUMP_ENABLE=true
os.environ["PYPTO_DATADUMP_ENABLE"] = "true"
# 配置验证选项
@pypto.frontend.jit(
runtime_options={"run_mode": pypto.RunMode.NPU},
verify_options={
"enable_pass_verify": True,
"pass_verify_save_tensor": True
}
)
def kernel(...):
...
Dump数据输出路径#
output/output_*/dump_tensor_*/device_{deviceId}/
└── {taskId}_{seqNo}_{callopMagic}_{rootHash}_{funcHash}_{rawMagic}_{timeStamp}_{dataType}_{input/output}{index}.tdump
数据处理工具#
工具位置: tools/verifier/parse_dump_tensors.py
主要功能:
解析dump的二进制数据(.tdump文件),提取tensor数据为.data文件
自动合并分片tensor为完整的raw tensor(针对多个task处理同一raw tensor的场景)
支持codegen pass tensor对比验证(需配合
enable_pass_verify使用)
使用方法:
# 基本用法(未使能enable_pass_verify,不进行验证)
python3 tools/verifier/parse_dump_tensors.py \
--dump_tensor_path output/output_20260101120000/dump_tensor_20260101120000/device_0
# 带验证的用法(需先开启enable_pass_verify并运行算子)
python3 tools/verifier/parse_dump_tensors.py \
--dump_tensor_path output/output_20260101120000/dump_tensor_20260101120000/device_0 \
--verify_path output/output_20260101120000/verify_20260101120000
参数说明:
参数 |
必需/可选 |
说明 |
默认值 |
|---|---|---|---|
|
必需 |
dump数据目录路径,指向 |
无 |
|
可选 |
verify结果目录路径(包含verify_graph_data_metainfo.csv) |
|
输出文件:
output/output_*/dump_tensor_*/device_0/
├── *.data # 提取的tensor数据文件
├── raw_{rawMagic}_{dataType}_{ioflag}.data # 合并后的raw tensor(如有分片)
└── ../ # 上级目录生成对比结果报告
└── verify_task_result_cmp~{pass_full_name}~{timestamp}.csv # 对比验证结果报告
注:
ioflag使用i(输入)或o(输出);pass_full_name为自动检测到的 Pass 全名(如Pass_36_CodegenPreproc)。
verify_task_result_cmp~{pass_full_name}~{timestamp}.csv字段说明:
字段前缀说明:
B>前缀:表示上板dump的原始数据A>前缀:表示验证数据(来自pass verify)AB>前缀:表示对比验证结果
基础信息字段:
字段 |
说明 |
|---|---|
NO. |
序号(按执行时间戳排序) |
B>version |
dump数据格式版本号(当前为1) |
B>opId |
Operation ID |
B>funcId |
Function ID |
B>taskId |
任务ID |
B>blockIdx |
Block索引 |
ROOT_CALL:opmagic |
算子调用magic标识 |
ROOT_CALL:rawmagic |
原始tensor magic标识 |
B>:validshape |
tensor实际shape |
B>OP_ATTR_SYM_OFFSET |
tensor在raw tensor中的偏移 |
B>:rawshape |
原始完整tensor的shape |
B>tensorAddr |
tensor内存地址 |
B>:datatype |
数据类型(字符串,如FP32、INT8) |
IO_FLAG |
输入/输出标记(i/o) |
B>seqNo |
序列号 |
B>TIMESTAMP |
时间戳 |
B>EXEC_TIMESTAMP |
执行时间戳(输入取execStart,输出取execEnd) |
ROOT_FUNC:hash |
Root Function hash值 |
FUNC:hash |
Function hash值 |
B>loopVarInfos |
循环变量信息(匹配成功时为”=”,否则为字符串形式) |
LOOP_INFO |
验证数据的循环信息(匹配成功时填充,否则为空) |
验证对比字段(启用–verify_path时):
字段 |
说明 |
|---|---|
A>PHASE_NAME |
验证数据的阶段名称(如Pass_36_CodegenPreproc) |
A>FILENAME |
验证数据文件名(仅保留文件名,不含路径) |
A>:datatype |
验证数据的数据类型 |
A>:validshape |
验证数据的shape |
A>:rawmagic |
验证数据的raw magic标识 |
A>:opcode |
验证数据的opcode |
A>:opmagic |
验证数据的op magic标识 |
A>OP_ATTR_SYM_OFFSET |
验证数据的偏移 |
A>OP_IO_FLAG |
验证数据的输入/输出标记 |
PATH_FUNC:hash |
Path Function hash值 |
AB>RESULT |
对比结果:PASS、FAIL、SKIP |
AB>RESULT_REASON |
未对比原因(SKIP时,如”unsupported dtype: BOTTOM”) |
AB>rtol/atol |
容差参数 |
对比验证流程:
数据匹配:通过
ROOT_CALL:opmagic、ROOT_CALL:rawmagic、IO_FLAG、B>OP_ATTR_SYM_OFFSET匹配上板数据与验证数据容差配置:根据数据类型自动选择容差
FP32/FP64:标准容差(rtol=1e-3, atol=1e-3)
FP16/BF16/FP8:放宽容差(rtol=1e-2, atol=1e-2)
Shape处理:自动处理shape不一致的对比(取公共部分)
不支持类型:HF4、HF8、BOTTOM等类型标记为SKIP
Raw Tensor合并说明:
当多个task处理同一个raw tensor的不同分片时,脚本会自动:
按
ROOT_CALL:rawmagic分组根据
B>OP_ATTR_SYM_OFFSET和B>:validshape计算切片位置合并所有分片数据到完整raw tensor
生成的文件命名为:
raw_{rawMagic}_{dataType}_{ioflag}.data(ioflag为i或o)
CPU模拟计算数据dump#
功能概述#
支持dump CPU模拟计算的结果,可用于精度定位。通过dump模拟计算数据,将精度出错的pass和前面正确的pass用对比脚本进行对比,找到能够匹配上首次出现精度问题的op。
启用方式#
# 配置验证选项
@pypto.frontend.jit(
debug_options={"compile_debug_mode": 1},
verify_options={
"enable_pass_verify": True,
"pass_verify_save_tensor": True,
"pass_verify_pass_filter": ["InferParamIndex", "CodegenPreproc"] # 可配置dump的具体pass
}
)
def kernel(...):
...
注:
pass_verify_pass_filter不指定时默认校验特定pass;指定"all"校验所有pass;指定具体pass名称列表可仅dump所需pass的模拟计算数据。
Dump数据输出路径#
执行结束后,在{work_path}/output/output_*/目录(*代表时间戳)下生成verify_*目录,存放模拟计算数据与检测结果文件:
├── tensor_graph # 保存前端初始计算图模拟计算后的中间数据,作为基础数据
│ ├── *.data
│ └── ...
├── Pass_{PASS_SEQ}_{PASS_NAME} # 保存中间pass计算图模拟计算后的中间数据,作为待测数据
│ ├── *.data
│ └── ...
├── verify_graph_data_metainfo.csv # 结果报告,保存中间数据元信息及对应数据文件名
├── verify_graph_result_brief.csv # 精度比对摘要(PASS/FAIL/NO_COMPARE、误差统计等)
├── verify_graph_result_brief.log # 精度比对异常详情(失败项、异常路径、错误明细)
└── interpreter.log # 校验结果与 interpreter 执行日志
数据处理工具#
工具位置: tools/verifier/pass_compare.py
主要功能:
根据dump的verify_graph_data_metainfo.csv里面的tensor信息,将两个pass间能够匹配上的op的输出tensor进行对比,找到出错的op。
使用方法:
# 基本用法(两个pass在同一verify目录下)
python3 tools/verifier/pass_compare.py \
--p ExpandFunction RemoveUndrivenView \
--verify_path output/output_20260101120000/verify
# 指定函数名过滤对比范围
python3 tools/verifier/pass_compare.py \
--p ExpandFunction RemoveUndrivenView \
--verify_path output/output_20260101120000/verify \
--func TENSOR_LOOP_s2_Unroll8_PATH0_hiddenfunc0_20
# 两个pass在不同verify目录下
python3 tools/verifier/pass_compare.py \
--p ExpandFunction RemoveUndrivenView \
--verify_path output/output_20260101120000/verify output/output_20260101130000/verify
参数说明:
参数 |
必需/可选 |
说明 |
默认值 |
|---|---|---|---|
|
必需 |
指定需要比较的两个pass的名称,以空格分隔。第一个为待测pass(可能有精度问题),第二个为golden pass(精度正确的基准) |
无 |
|
必需 |
verify结果目录路径。提供一个值时两个pass共用同一目录;提供两个值时分别对应两个pass的目录 |
无 |
|
可选 |
指定待比较的函数名称列表,以空格分隔。不指定则对比所有函数 |
空(对比所有) |
|
可选 |
绝对误差容差 |
|
|
可选 |
相对误差容差 |
|
|
可选 |
打印差异最大的前k行 |
|
输出文件:
output/output_*/verify_*/
├── verify_graph_result_cmp~Pass_{NN}_{GoldenPass}~Pass_{NN}_{OutputPass}~{timestamp}.csv # 对比验证结果报告
└── verify_graph_result_cmp~Pass_{NN}_{GoldenPass}~Pass_{NN}_{OutputPass}~{timestamp}.DETAIL/ # 逐tensor差异明细(仅对比失败时生成)
└── {tensor_filename}.csv
注:
{NN}为pass序号(两位补零),{GoldenPass}为golden pass名称,{OutputPass}为待测pass名称,{timestamp}为微秒级时间戳。工具会自动确保序号大的pass作为待测pass、序号小的pass作为golden pass,无需用户手动排序。
verify_graph_result_cmp~{Pass_a}~{Pass_b}~{timestamp}.csv字段说明:
字段前缀说明:
B>前缀:表示待测pass(后一个、精度可能有问题的pass)的数据信息A>前缀:表示golden pass(精度正确的pass)的数据信息AB>前缀:表示对比验证结果无前缀:表示两个pass共有的公共属性
公共信息字段:
字段 |
说明 |
|---|---|
NO. |
序号(按待测pass时间戳排序) |
PATH_FUNC:func_magicname |
Path Function的magic名称 |
PATH_FUNC:funcmagic |
Path Function的magic标识 |
PATH_FUNC:hash |
Path Function的hash值 |
LOOP_INFO |
循环变量信息 |
:symbol |
tensor符号名 |
:validshape |
tensor实际shape |
:datatype |
数据类型(字符串,如FP32、BF16、INT8) |
OP_ATTR_SYM_OFFSET |
tensor在raw tensor中的偏移 |
OP_IO_FLAG |
输入/输出标记 |
待测pass数据字段(B>前缀):
字段 |
说明 |
|---|---|
B>PHASE_NAME |
待测pass的阶段名称 |
B>TIMESTAMP |
时间戳 |
B>FILENAME |
数据文件名 |
B>FUNC:hash |
Function hash值 |
B>FUNC:funcmagic |
Function magic标识 |
B>ROOT_CALL:opmagic |
算子调用magic标识 |
B>ROOT_CALL:rawmagic |
原始tensor magic标识 |
B>:opmagic |
op magic标识 |
B>:opcode |
操作类型(如COPY_IN、COPY_OUT、VIEW、ASSEMBLE等) |
B>:rawmagic |
raw tensor magic标识 |
B>:magic |
tensor magic标识 |
B>:rawshape |
原始完整tensor的shape |
B>:format |
数据格式 |
B>:shape |
tensor的shape |
B>EVAL:dynvalidshape |
动态shape求值结果 |
B>ROOT_FUNC:hash |
Root Function hash值 |
golden pass数据字段(A>前缀):
字段 |
说明 |
|---|---|
A>PHASE_NAME |
golden pass的阶段名称 |
A>TIMESTAMP |
时间戳 |
A>FILENAME |
数据文件名 |
A>FUNC:hash |
Function hash值 |
A>FUNC:funcmagic |
Function magic标识 |
A>ROOT_CALL:opmagic |
算子调用magic标识 |
A>ROOT_CALL:rawmagic |
原始tensor magic标识 |
A>:opmagic |
op magic标识 |
A>:opcode |
操作类型 |
A>:rawmagic |
raw tensor magic标识 |
A>:magic |
tensor magic标识 |
A>:rawshape |
原始完整tensor的shape |
A>:format |
数据格式 |
A>:shape |
tensor的shape |
A>EVAL:dynvalidshape |
动态shape求值结果 |
A>ROOT_FUNC:hash |
Root Function hash值 |
对比结果字段(AB>前缀):
字段 |
说明 |
|---|---|
AB>RESULT |
对比结果:PASS(通过)、FAIL(失败)、SKIP(跳过) |
AB>RESULT_REASON |
跳过或失败原因(SKIP时,如” |
AB>rtol/atol |
实际使用的容差参数 |
AB>fail_cnt/warn_cnt/tol_cnt |
失败/警告/容忍的元素计数 |
AB>total_cnt/zero_cnt/infnan_cnt |
总数/零值/inf或nan元素计数 |
AB>mae |
平均绝对误差(Mean Absolute Error) |
AB>mae_top8 |
误差最大的前8个元素的平均绝对误差 |
AB>mae_top1permil |
误差最大的前千分之一元素的平均绝对误差 |
AB>mre |
平均相对误差(Mean Relative Error) |
AB>mre_top8 |
误差最大的前8个元素的平均相对误差 |
AB>mre_top1permil |
误差最大的前千分之一元素的平均相对误差 |
数据统计字段:
字段 |
说明 |
|---|---|
A>max / B>max |
golden/待测数据的最大值 |
A>min / B>min |
golden/待测数据的最小值 |
A>avg / B>avg |
golden/待测数据的平均值 |
A>aavg / B>aavg |
golden/待测数据的绝对值平均值 |
A>zero / B>zero |
golden/待测数据的零值个数 |
A>infnan / B>infnan |
golden/待测数据的inf/nan个数 |
对比验证流程:
读取元信息:从
verify_graph_data_metainfo.csv读取两个pass的tensor元信息Pass排序:自动确保序号大的pass作为待测pass(B>)、序号小的pass作为golden pass(A>),如需交换则同步交换verify路径
匹配键选择:根据pass序号自动选择匹配键
两个pass都 >= ExpandFunction:使用
:magic匹配待测pass >= InferParamIndex 且 golden pass在[ExpandFunction, InferParamIndex)区间:使用
ROOT_CALL:rawmagic匹配(仅匹配COPY_IN/COPY_OUT操作)两个pass都 >= InferParamIndex:启用leaf function匹配逻辑(额外校验
ROOT_CALL:opmagic)
分组匹配:按
PATH_FUNC:func_magicname和LOOP_INFO分组,在相同分组内按匹配键寻找tensor对codegen模式下COPY_IN操作通过
INPUT:rawmagic匹配
跳过检查:validshape含0、或ASSEMBLE/COPY_OUT的输入validshape含0的记录直接跳过
包含性检查:验证待测tensor是否被golden tensor包含(基于offset和shape范围)
opcode匹配:支持等价opcode匹配(如VIEW≈L1_TO_L0A/L1_TO_L0B、COPY_OUT≈ASSEMBLE、COPY_IN≈VIEW、A_MUL_B≈A_MULACC_B)
数据对比:读取
.data文件,按offset切片后转为float64进行逐元素对比;ASSEMBLE/COPY_OUT操作使用输入tensor的shape进行切片不支持类型:非BF16/FP32/FP16/INT32/INT8/INT64/INT16的类型标记为SKIP
算子级别的输入输出tensor dump#
功能概述#
支持整网中算子级别的输入输出上板dump的能力。
启用方式#
在脚本运行目录下创建acl.json文件,内容如下:
{
"dump":{
"dump_path":"/your/path",
"dump_mode":"all",
"dump_debug":"off",
"dump_op_switch":"on"
}
}
在要执行的用例test.py中添加如下配置:
import torch
import torch_npu
torch.npu.init_dump()
torch.npu.set_dump("acl.json")
Dump数据输出路径#
数据输出路径就是acl.json里面配置的dump_path,在该路径下会生成如下文件:
/your/path
└── 20260415084134/0
└── TENSOR_batchmatmul_3d_kernel.TENSOR_batchmatmul_3d_kernel.29.46.1776242496294291
调用CANN已有的工具解析该文件,命令如下:
进入${INSTALL_DIR}/tools/operator_cmp/compare,${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。以root用户安装为例,安装后文件默认存储路径为:/usr/local/Ascend/cann。
python3 msaccucmp.py convert -d /your/path/20260415084134/0 -out /your/path/20260415084134/0/out
解析后生成如下npy文件:
/your/path
└── 20260415084134/0
├── out/
│ ├── TENSOR_batchmatmul_3d_kernel.TENSOR_batchmatmul_3d_kernel.29.46.1776242496294291.input.0.npy
│ ├── TENSOR_batchmatmul_3d_kernel.TENSOR_batchmatmul_3d_kernel.29.46.1776242496294291.input.1.npy
│ └── TENSOR_batchmatmul_3d_kernel.TENSOR_batchmatmul_3d_kernel.29.46.1776242496294291.input.2.npy
└── TENSOR_batchmatmul_3d_kernel.TENSOR_batchmatmul_3d_kernel.29.46.1776242496294291