pypto.experimental.gather_in_ub#
产品支持情况#
产品 |
是否支持 |
|---|---|
Ascend 950PR/Ascend 950DT |
√ |
Atlas A3 训练系列产品/Atlas A3 推理系列产品 |
√ |
Atlas A2 训练系列产品/Atlas A2 推理系列产品 |
√ |
功能说明#
该接口为定制接口,约束较多。不保证稳定性。
该算子支撑稀疏注意力机制,能力为将选中的 token 的 kv cache 从 GM(Global Memory)加载到UB(Unified Buffer)中,支持Page Attention。
函数原型#
gather_in_ub(param: Tensor, indices: Tensor, block_table: Tensor,
block_size: int, axis: int) -> Tensor
参数说明#
参数名 |
输入/输出 |
说明 |
|---|---|---|
param |
输入 |
源操作数。 |
indices |
输入 |
源操作数。 |
block_table |
输入 |
源操作数。 |
block_size |
输入 |
源操作数。 |
axis |
输入 |
源操作数。 |
返回值说明#
返回输出 Tensor,Tensor的数据类型和 param 相同,Shape 为[k, hidden_dim],即 选中 token kv cache。
调用示例#
TileShape设置示例#
调用该operation接口前,应通过set_vec_tile_shapes设置TileShape。
TileShape 的维度设置须与输出张量保持一致,用于控制输出 Tile 块的大小。
以输入\( param[token_size,hidden_dim]\) 、索引 \(indices[1,k]\) 、轴 \(\text{axis}=-2\) 、输出 \(output[k,hidden_dim]\) 为例:
设 TileShape 为\([k_1, hidden_dim_1]\),该配置直接作用于输出 output 的各维度,同时映射至输入与索引。其中 \(k_1\) 切分 indices 的 k 维 ,\( hidden_dim_1\) 切分 param 的特征维 \(hidden_dim\) 。Tile 内存占用须满足约束 \(b_1 \cdot k_1 \cdot hidden_dim_1 \cdot \text{sizeof}(\mathbf{output}) < \text{UB_Size}\)
接口调用示例#
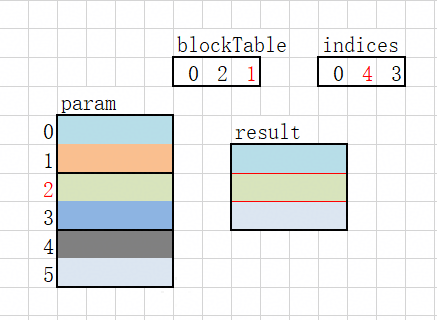
考虑以上场景,indices为topk结果,block_table为Page Attention的页表,param 为 kv cache,block_size为2。最终的结果是将token的kv cache 收集起来。
以 token id 4为例(在图中标红),根据blockSize计算出实际偏移:
blockIdx = 4 / 2; //计算对应的逻辑块,第2个逻辑块
tail = 4 % 2; //计算块内偏移,偏移为0
slcBlockIdx = blockTable[0, blockIdxInBatch]; //查表,得到该块实际偏移,对应第1个物理块
offsets = slcBlockIdx * blockSize + tail;//计算出实际的偏移,为2
对数据进行搬运
param = pypto.tensor([6, 4], pypto.DT_FP32)
indices = pypto.tensor([1, 3], pypto.DT_INT32)
blockTable = pypto.tensor([1, 3], pypto.DT_INT32)
blockSize = 2
axis = -2
result = pypto.experimental.gather_in_ub(param , indices , blockTable, blockSize , axis)
结果示例如下:
输入数据param :
[
# token 0
[ 0, 1, 2, 3],
# token 1
[ 10, 11, 12, 13],
# token 2
[ 20, 21, 22, 23],
# token 3
[ 30, 31, 32, 33],
# token 4
[ 40, 41, 42, 43],
# token 5
[ 50, 51, 52, 53],
]
输入数据indices : [0, 4, 3]
输入数据blockTable : [0, 2, 1]
输出数据out:
[
[ 0, 1, 2, 3],
[ 20, 21, 22, 23],
[ 50, 51, 52, 53],
]